很多 MySQL 文章会把连接器、解析器、优化器、Undo Log、Redo Log、Binlog、Change Buffer、锁机制逐个讲一遍。每个概念单看都不难,但放在一起就容易变成一张散开的知识卡片。
更好的读法是:先抓住一条 SQL,然后沿着它在 MySQL 内部走过的路径往下看。
本文就围绕这条语句展开:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
源码版本说明:文中的源码位置基于 MySQL
mysql-5.7.44,正文里的路径均相对 MySQL 源码根目录,例如sql/sql_insert.cc:428。
它看起来只是往 orders 表里插入一行数据,但 InnoDB 实际上要完成几件事:
- Server 层要把 SQL 解析成一次存储引擎调用;
- InnoDB 要找到这条记录应该写入哪一个 B+ 树叶子页;
- 写入前要准备回滚信息,写入后要保证宕机可恢复;
- 二级索引可能会触发额外的随机 IO,也可能被 Change Buffer 延迟处理;
- 最后还要通过 Redo Log 和 Binlog 的两阶段提交保证事务和复制一致。
先看一张总图。
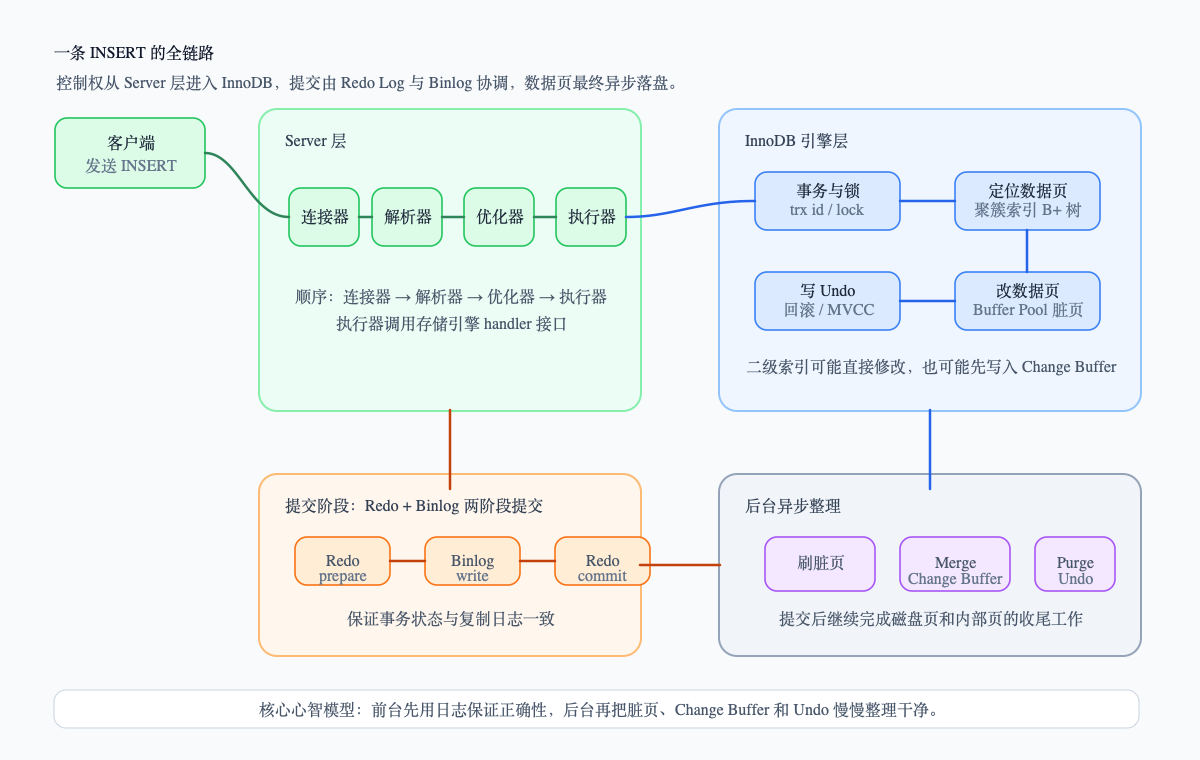
这张图里最重要的不是每一个框,而是控制权的移动方向:
SQL 先经过 Server 层,真正的数据写入发生在 InnoDB,事务提交靠 Redo Log 和 Binlog 协调,数据页最终由后台线程慢慢刷回磁盘。
1. Server 层:把 SQL 变成一次引擎调用
客户端发起 INSERT 后,先进入 MySQL Server 层。
这一层不直接修改 InnoDB 的数据页,它主要负责把 SQL 变成一个明确的执行动作。
大致路径是:
客户端-> 连接器-> 解析器-> 预处理-> 优化器-> 执行器-> InnoDB 存储引擎
连接器负责认证、权限、连接状态和线程上下文。解析器做词法分析、语法分析,把 SQL 变成语法树。预处理阶段会确认表、列、权限等信息是否有效。
对于 INSERT 来说,优化器的发挥空间没有复杂 SELECT 那么大。它主要确认目标表、目标列、写入路径,以及遇到 ON DUPLICATE KEY UPDATE 这类语句时该怎么处理。
最后,执行器调用 InnoDB 暴露出来的 handler 接口。可以把这一步理解成:
Server 层:这条记录要写入 orders 表。InnoDB:好的,我来负责真正的数据结构修改和事务保证。
对应到 MySQL 5.7 源码,INSERT 的入口在 sql/sql_insert.cc:428 的 Sql_cmd_insert::mysql_insert()。真正把一行记录交给存储引擎的位置,在 write_record() 里调用 table->file->ha_write_row(...),普通插入路径可以看 sql/sql_insert.cc:1895,带重复键处理的路径可以看 sql/sql_insert.cc:1538。
ha_write_row() 是 Server 层 handler 的统一入口,定义在 sql/handler.cc:8153,里面最终会调到具体存储引擎实现的 write_row()。如果表是 InnoDB,就会进入 storage/innobase/handler/ha_innodb.cc:7507 的 ha_innobase::write_row()。
从这里开始,问题才进入 InnoDB 的核心地带。
Server 层读的是哪份元数据?
这里有个容易混淆的点:连接器、解析器、优化器并不是都去读同一份“表元数据”。
在 MySQL 5.7 里,表结构主要分成两层:
datadir/db_name/orders.frm Server 层表定义orders.ibd InnoDB 数据页和索引页ibdata1 InnoDB 系统表空间,包含 SYS_TABLES / SYS_COLUMNS / SYS_INDEXES 等内部字典
.frm 是 Server 层理解表结构的入口。它保存列、类型、索引、表选项、分区信息,以及这个表对应的存储引擎。InnoDB 还会在自己的内部数据字典里保存表、列、索引、表空间等信息,也就是 SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS、SYS_TABLESPACES 这些内部表。
所以这几个阶段可以这样分:
| 阶段 | 它读什么 | 说明 |
|---|---|---|
| 连接器 | ACL 权限缓存,来源于 mysql.user、mysql.db、mysql.tables_priv 等授权表 |
负责认证和权限上下文,不知道目标业务表是什么引擎 |
| 解析器 | SQL 文本 | 只把 INSERT INTO orders ... 解析成语法结构和表名引用,不真正打开 orders 表 |
| 预处理 / 打开表 | TABLE_SHARE,来源于 table_def_cache,缓存未命中时读取 .frm |
确认表存在、列存在、字段列表合法,并从 .frm 得到表引擎 |
| 优化器 | 已打开的 TABLE / TABLE_SHARE,以及 handler 暴露的统计信息 |
对普通 INSERT ... VALUES 优化空间很小;INSERT ... SELECT 的 SELECT 部分才会进入更完整的优化 |
| 执行器 | TABLE 上的 handler |
根据 TABLE_SHARE::db_type() 创建具体 handler,例如 InnoDB 的 ha_innobase |
换句话说,连接器不会在连接阶段就知道 orders 是 InnoDB 还是 MyISAM。这个信息是在打开表定义时,从 table_def_cache 或 .frm 填充到 TABLE_SHARE 里的。
源码上可以看到这条链路:连接认证入口在 sql/sql_connect.cc:692,会调用 acl_authenticate(...);授权缓存来自 mysql.user 等表,加载逻辑可以看 sql/auth/sql_auth_cache.cc:1486 附近。SQL 解析入口在 sql/sql_parse.cc:1486 到 sql/sql_parse.cc:1492。而 INSERT 真正打开目标表的位置在 sql/sql_insert.cc:471 的 open_tables_for_query(...)。
打开表时,Server 层会先查 table_def_cache。如果没有命中,就通过 sql/table.cc:694 的 open_table_def() 读取 .frm 文件,并把结果填入 TABLE_SHARE。存储引擎类型来自 .frm 里的 db type 字段,相关解析可以看 sql/table.cc:1118、sql/table.cc:1712、sql/table.cc:1954。最后根据 share->db_type() 创建具体 handler,入口在 sql/table.cc:2300 和 sql/handler.cc:653。
这也是 MySQL 5.7 和 8.0 的一个重要差异:5.7 仍然是 .frm + InnoDB SYS_* 这套双层元数据;8.0 才把 .frm 去掉,换成事务型数据字典。
2. InnoDB 先找位置:这条记录要落在哪个页?
InnoDB 里,表数据本身就是一棵按照主键组织的 B+ 树,也叫聚簇索引。
如果 orders 使用自增主键,那么这条 SQL 在真正插入前,InnoDB 需要先拿到一个新的主键值,比如:
id = 10000001
然后它会根据这个主键值,在聚簇索引 B+ 树中找到对应的叶子页。
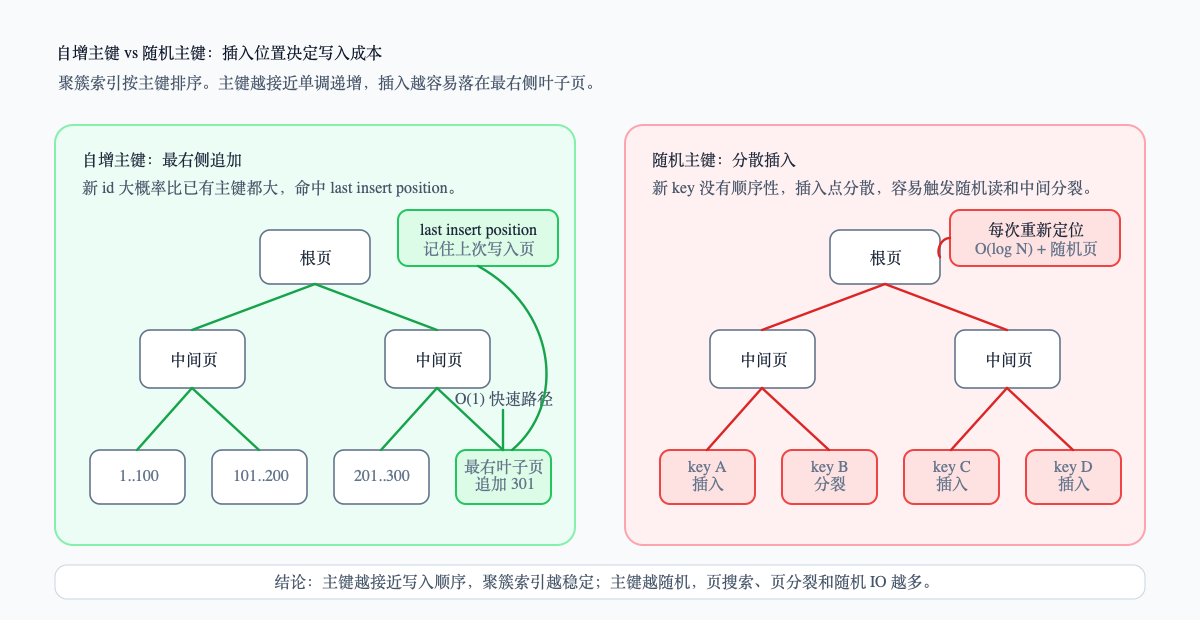
自增主键为什么插入快?
自增主键有一个很大的优势:新记录通常会落在 B+ 树最右侧的叶子页。
InnoDB 会缓存上一次插入的位置。只要新的主键值继续递增,而且上一次插入的页还适合继续写,就可以直接追加到这个叶子页的末尾,而不是每次都从根节点重新查找。
这部分在源码里分成两层:自增值生成在 storage/innobase/handler/ha_innodb.cc:16757 的 ha_innobase::get_auto_increment(),自增锁逻辑在 storage/innobase/handler/ha_innodb.cc:7388 的 ha_innobase::innobase_lock_autoinc()。B+ 树页内的“上次插入”信息可以看 storage/innobase/page/page0cur.cc:91 的 page_cur_try_search_shortcut(),以及 storage/innobase/page/page0cur.cc:1472 更新 PAGE_LAST_INSERT 和 PAGE_DIRECTION 的逻辑。
这就是自增主键适合高并发写入的根本原因:
- 定位路径短,大多数时候可以命中“上次插入页”;
- 页满时更容易发生右分裂,旧页不用搬走一半数据;
- 数据页整体更紧凑,磁盘写入也更接近顺序写。
随机主键就不同了。UUID v4 这类值没有单调性,插入位置会散落在 B+ 树各处。每次写入都可能命中不同叶子页,页分裂也更容易发生在中间位置。
对比一下:
| 维度 | 自增主键 | UUID / 随机主键 |
|---|---|---|
| 插入位置 | B+ 树最右侧 | 分散在各个叶子页 |
| 定位路径 | 容易命中上次插入位置 | 通常要完整搜索 |
| 页分裂 | 多数是右分裂 | 容易中间分裂 |
| 页填充率 | 更高 | 更容易碎片化 |
| IO 模式 | 更接近顺序写 | 更容易随机读写 |
所以,很多业务表会优先选择自增 ID、Snowflake ID 这类单调递增或大体递增的主键,而不是完全随机的 UUID。
页分裂的源码可以看 storage/innobase/btr/btr0btr.cc:2514 的 btr_page_split_and_insert()。其中 storage/innobase/btr/btr0btr.cc:1833 的 btr_page_get_split_rec_to_right() 专门判断“连续向右插入”的分裂位置,注释里也明确提到 sequential inserts。
3. 真正被修改的不是“一条记录”,而是一组页
找到聚簇索引叶子页后,InnoDB 并不是简单地把一行数据塞进去就结束。
一次 INSERT 通常会影响这些对象:
- 聚簇索引数据页:写入完整行记录;
- Undo 页:记录必要的回滚信息;
- Redo Log Buffer:记录物理修改,用于宕机恢复;
- 二级索引页:给每个二级索引插入对应索引项;
- Change Buffer:如果非唯一二级索引目标页不在内存,可能先记入这里;
- 事务系统页和锁结构:维护事务 ID、回滚段、锁等待关系等。
这些页大多会先进入 Buffer Pool。修改完成后,它们会被标记为脏页,但不会马上写回磁盘。
这点非常关键:事务提交成功,不等于数据页已经落盘。
InnoDB 真正依赖的是 WAL,也就是先写日志,再慢慢刷数据页。
这条写入路径在 InnoDB 内部会继续进入 storage/innobase/row/row0mysql.cc:1856 的 row_insert_for_mysql(),再到 storage/innobase/row/row0ins.cc:3795 的 row_ins_step()。row_ins() 会遍历表上的索引,逐个插入索引项,关键循环在 storage/innobase/row/row0ins.cc:3750。
4. Redo、Undo、Binlog:三个东西解决三个问题
这部分最容易混在一起。
可以先用一句话区分:
- Undo Log 解决“事务能不能回滚、旧版本能不能读到”;
- Redo Log 解决“宕机后已经提交的数据能不能恢复”;
- Binlog 解决“复制和按时间点恢复能不能重放这条 SQL 的逻辑变化”。
它们不是同一种日志。
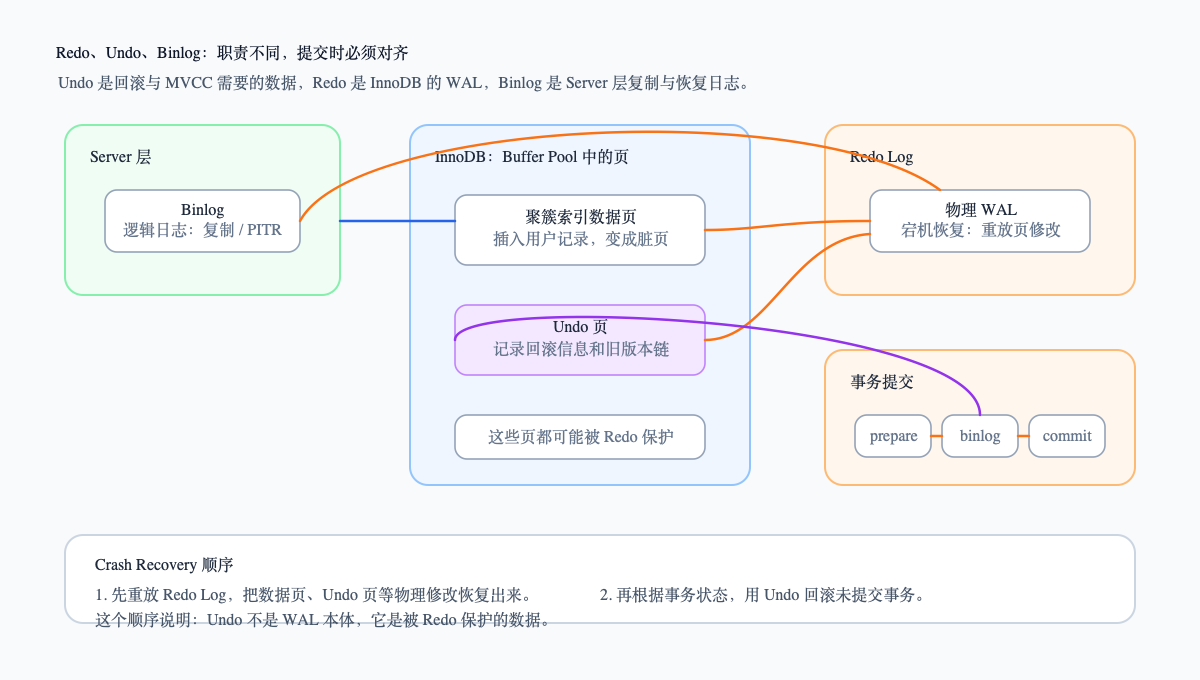
用一条 INSERT 看三类日志大概长什么样
继续沿用这条 SQL:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
假设它最终生成的自增主键是:
id = 10000001
那么三类日志可以用下面这个“概念化 sample”来理解。注意,这不是 MySQL 文件里的逐字内容。Redo Log 和 Undo Log 都是 InnoDB 内部格式;Binlog 也会受 binlog_format 影响。
先看 Undo Log。
Undo record: TRX_UNDO_INSERT_RECtrx_id: trx_12345table: ordersindex: PRIMARYrow key: id = 10000001action: rollback 时删除这条新插入的聚簇索引记录
INSERT 的 Undo 不需要保存“旧值”,因为这行记录原来不存在。它真正要支持的是:如果事务回滚,就能根据这条 undo 记录把刚插入的记录删掉。后续如果有一致性读需要判断这行记录是否对某个 ReadView 可见,也会用到记录上的事务信息和 undo 链。
再看 Redo Log。
Redo records:1. 修改 undo 页space_id = undo tablespacepage_no = undo page 42op = 写入 TRX_UNDO_INSERT_REC2. 修改聚簇索引叶子页space_id = orders.ibd 的表空间 idpage_no = PRIMARY leaf page 1088op = 在页内插入记录 (id=10000001, user_id=98765, status=1)3. 修改二级索引页或 Change Buffer 页space_id = orders.ibd 或系统表空间page_no = idx_user_id leaf page / ibuf pageop = 插入二级索引项 (user_id=98765, pk=10000001)
Redo 关心的是“哪个表空间的哪个页发生了什么物理修改”。它不是 SQL,也不主要用表名来描述变化。宕机恢复时,InnoDB 会根据这些物理日志把数据页、undo 页、Change Buffer 页恢复到应该有的状态。
最后看 Binlog。Binlog 是 Server 层日志,主要服务复制和按时间点恢复。它记录的是逻辑变化。不同 binlog_format 下,样子不一样。
如果是 statement 格式,接近这样:
Query event:schema: mydbsql: INSERT INTO orders (user_id, status) VALUES (98765, 1)
如果是 row 格式,更接近这样:
Table_map event:table_id: 256schema: mydbtable: orderscolumns: id, user_id, statusWrite_rows event:after image:id = 10000001user_id = 98765status = 1
所以三者的观察角度完全不同:
| 日志 | 观察角度 | 这个 INSERT 里大概记录什么 |
|---|---|---|
| Undo Log | 事务回滚 / MVCC | 如果回滚,要删除 id=10000001 这条新记录 |
| Redo Log | 物理页恢复 | 哪些数据页、undo 页、索引页、Change Buffer 页被改了 |
| Binlog | 复制 / PITR | 这条逻辑写入,或这行数据的 after image |
把它们串起来看,就是:
写 Undo:以后回滚用写 Redo:宕机恢复用,保护 undo 页和数据页修改写 Binlog:复制和按时间点恢复用Redo prepare + Binlog + Redo commit:保证 InnoDB 和 Binlog 对同一事务达成一致
事务是怎么把三类日志串起来的?
事务不是流程里的某一个单独步骤,而是贯穿整条写入链路的上下文。
在 Server 层,一条连接对应一个 THD。THD 里有事务上下文,也有 Binlog 的事务缓存。在 InnoDB 层,这个连接会绑定一个 trx_t,InnoDB 的锁、Undo、事务 ID、提交状态都挂在这个 trx_t 上。
可以先把关系想成这样:
THD / Transaction_ctx-> binlog trx cache-> registered engines: InnoDBInnoDB trx_t-> trx_id-> locks-> undo records-> modified pages protected by redo
当这条 INSERT 真正写入时,InnoDB 会把当前事务 ID 写进聚簇索引记录的隐藏字段 DB_TRX_ID,再把指向 Undo 记录的位置写进 DB_ROLL_PTR。
所以一条新插入的聚簇索引记录,不只是业务字段:
orders clustered recordid = 10000001user_id = 98765status = 1DB_TRX_ID = 当前 InnoDB trx_t 的事务 IDDB_ROLL_PTR = 指向这条 insert undo 记录
这两个隐藏字段把“行记录”和“事务”接了起来:
DB_TRX_ID用来判断这行是谁改的、对当前 ReadView 是否可见;DB_ROLL_PTR用来找到 Undo 记录,支持回滚和旧版本构造;- Redo Log 保护的是这个事务改过的页,包括数据页、Undo 页、Change Buffer 页;
- Binlog 则先进入
THD的事务缓存,等提交时再和 InnoDB 的 prepare / commit 协调。
换句话说,Undo 是事务的后路,Redo 是页修改的保险,Binlog 是 Server 层对外复制和恢复的记录。事务提交时,MySQL 要保证这三件事最后指向同一个结果。
这条链路在源码里可以对应起来:storage/innobase/handler/ha_innodb.cc:1728 的 thd_to_trx() 从 THD 取 InnoDB 事务对象;storage/innobase/handler/ha_innodb.cc:2662 的 check_trx_exists() 会在需要时创建它;storage/innobase/btr/btr0cur.cc:2981 会生成 Undo 并返回 roll_ptr;Binlog 的事务缓存管理可以看 sql/binlog.cc:865 的 binlog_cache_mngr。
Undo Log 不是 WAL
一个常见误解是:Undo Log 也是 WAL。
更准确的说法是:
Redo Log 才是 InnoDB 的 WAL。Undo Log 本身是被 Redo Log 保护的数据。
Undo Log 存在 undo 表空间里,本质上也是一种数据页。写入 undo 记录时,会修改 undo 页;修改 undo 页这个动作,也要写入 Redo Log。
所以一次 INSERT 至少会出现两类 redo:
1. 修改 undo 页:记录一条用于回滚的 undo 记录2. 修改数据页:把新行写入聚簇索引叶子页
Redo Log 保护的不只是用户数据页,也包括 Undo 页、Change Buffer 页等 InnoDB 内部页。
源码里可以从 storage/innobase/btr/btr0cur.cc:2981 看到聚簇索引插入前会调用 trx_undo_report_row_operation(...),生成插入对应的 Undo 记录。这个函数定义在 storage/innobase/trx/trx0rec.cc:1844,其中 storage/innobase/trx/trx0rec.cc:1989 会调用 trx_undo_page_report_insert(...) 写入 insert undo。
两阶段提交保证 Redo 和 Binlog 一致
MySQL 需要同时维护 InnoDB 的 Redo Log 和 Server 层的 Binlog。
如果只写了 Redo,没写 Binlog,主库自己能恢复,但从库不知道这次修改。如果只写了 Binlog,没提交 Redo,复制链路和主库状态又可能不一致。
所以提交时要走两阶段提交:
1. Redo Log 写入 prepare 状态2. Server 层写 Binlog3. Redo Log 改成 commit 状态
这样宕机恢复时,MySQL 可以根据 Redo 和 Binlog 的状态判断事务到底应该提交还是回滚。
生产环境里常见的“安全配置”是:
innodb_flush_log_at_trx_commit = 1sync_binlog = 1
前者控制 Redo Log 每次提交时是否刷盘,后者控制 Binlog 每次提交时是否刷盘。所谓“双 1”,追求的是 crash-safe,代价是更高的刷盘成本。
两阶段提交的 Server 层入口可以看 sql/handler.cc:2338 的 ha_prepare_low(),以及 sql/binlog.cc:8580 的 MYSQL_BIN_LOG::prepare()。Binlog group commit 的主流程在 sql/binlog.cc:9520 的 MYSQL_BIN_LOG::ordered_commit(),里面能看到 flush binlog、sync binlog、commit storage engine 这几个阶段。InnoDB 侧最终提交事务的入口是 storage/innobase/trx/trx0trx.cc:2409 的 trx_commit_for_mysql()。
写盘顺序:数据页可以早于提交,但不能早于 Redo
这里还有一个很容易绕住的点:事务提交、Redo 刷盘、数据页刷盘不是同一件事。
InnoDB 允许未提交事务改过的数据页提前刷盘。因为如果事务最后回滚,或者宕机后发现它没有提交,InnoDB 还可以根据 Undo 把这些修改撤回去。
但 InnoDB 不允许数据页早于对应的 Redo 刷盘。因为一旦数据页已经写进 .ibd,而描述这次页修改的 Redo 还没落盘,宕机后恢复系统就没法可靠判断这个页上的修改到底是什么状态。
所以真正的规则是:
数据页可以早于事务 commit 落盘。数据页不能早于对应 redo 落盘。
可以用四种情况理解:
| 场景 | 是否允许 | 宕机后怎么办 |
|---|---|---|
| Redo 已落盘,数据页没落盘,事务已提交 | 允许 | 用 Redo 把已提交修改重放回来 |
| Redo 已落盘,数据页已落盘,事务未提交 | 允许 | 先恢复现场,再用 Undo 回滚未提交事务 |
| Redo 已落盘,数据页已落盘,事务已提交 | 允许 | 数据页本身已经包含修改,恢复时按 LSN 判断是否还需要重放 |
| 数据页已落盘,但对应 Redo 没落盘 | 不允许 | 这会破坏 WAL,InnoDB 刷脏页时会避免这种顺序 |
每个脏页都会带着自己的最新修改 LSN。刷脏页之前,InnoDB 会先确保 Redo 至少刷到这个 LSN,然后才把这个页写回数据文件。
MySQL 5.7 源码里能直接看到这个保护动作:storage/innobase/buf/buf0flu.cc:1055 在刷脏页前调用 log_write_up_to(bpage->newest_modification, true),先把日志写到这个页最新修改对应的 LSN。随后 storage/innobase/buf/buf0flu.cc:1070 会把这个 LSN 写进页头的 FIL_PAGE_LSN。
因此,WAL 不是说“提交时必须立刻刷所有数据页”,而是说:
只要一个数据页要落盘,它所依赖的 Redo 必须已经先落盘。
5. Change Buffer:把随机 IO 延迟到以后
如果表上有多个二级索引,一次 INSERT 就不只改聚簇索引。
例如 orders 表上有一个普通二级索引:
KEY idx_user_id (user_id)
那么插入 (user_id = 98765, id = 10000001) 时,InnoDB 还要往 idx_user_id 这棵 B+ 树里插入一条索引项。
问题在于,二级索引是按 user_id 排序的,和自增主键的插入顺序没有关系。目标叶子页很可能不在 Buffer Pool 中。
如果每个二级索引都立刻从磁盘读入目标页再修改,大量随机读就会把写入吞吐拖下来。
Change Buffer 的思路是:
如果非唯一二级索引的目标页不在内存,就先别读它,把“我要改这个页”这件事记下来。等以后这个页因为查询或其他写入被读进内存时,再把变更合并进去。
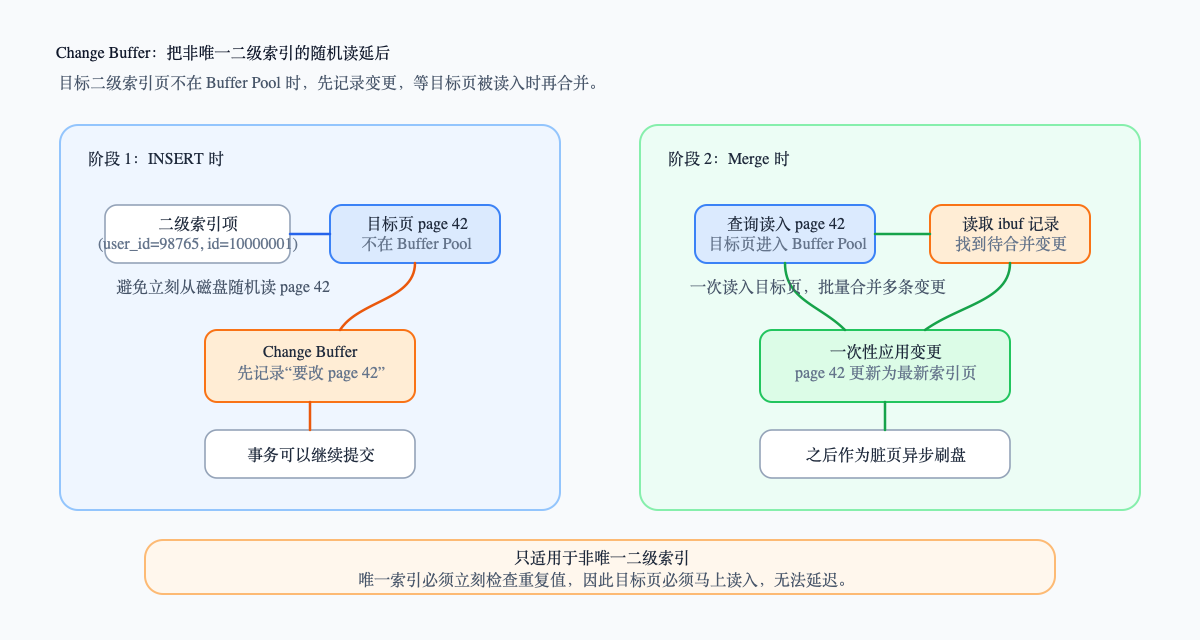
它的收益来自“合并”。
假设某个二级索引页在一段时间内被 1000 次插入命中:
不用 Change Buffer:可能触发 1000 次随机读使用 Change Buffer:先记录 1000 条变更等目标页被读入时一次性合并
这不是少写了数据,而是把“立即读随机页”改成了“延迟到将来顺手合并”。
不过 Change Buffer 有一个重要限制:只能用于非唯一二级索引。
原因也简单。唯一索引必须立即判断目标 key 是否已经存在。既然要判断是否存在,就必须读目标叶子页,随机 IO 逃不掉。
| 索引类型 | 能否使用 Change Buffer | 原因 |
|---|---|---|
| 聚簇索引 | 不能 | 数据行本身必须立即写入正确位置 |
| 唯一二级索引 | 不能 | 必须马上做唯一性检查 |
| 非唯一二级索引 | 可以 | 不需要立即判断重复 |
Change Buffer 自己也是持久化结构,也受 Redo Log 保护。因此它只影响性能路径,不影响事务正确性。
源码里,二级索引插入路径在 storage/innobase/row/row0ins.cc:3370 的 row_ins_sec_index_entry()。storage/innobase/row/row0ins.cc:2955 会为非临时、非空间索引打开 insert buffering 搜索模式。真正决定“目标页不在 Buffer Pool,就尝试写 Change Buffer”的逻辑在 storage/innobase/btr/btr0cur.cc:1095 到 storage/innobase/btr/btr0cur.cc:1132,成功后 cursor 会标记为 BTR_CUR_INSERT_TO_IBUF。Change Buffer 写入入口是 storage/innobase/ibuf/ibuf0ibuf.cc:3686 的 ibuf_insert(),合并入口可以看 storage/innobase/ibuf/ibuf0ibuf.cc:4426 的 ibuf_merge_or_delete_for_page()。
6. 锁:为什么有些 INSERT 会等?
大多数普通插入并不会互相阻塞。
InnoDB 为插入设计了 Insert Intention Lock,也就是插入意向锁。它是一种特殊的 Gap Lock,用来表达:
我准备往这个间隙里插入一条记录。
多个事务如果要往同一个间隙插入不同的值,它们的插入意向锁彼此兼容。这样并发 INSERT 才能跑起来。
真正会挡住插入的,通常是范围锁。
例如在 RR 隔离级别下:
-- 事务 ABEGIN;SELECT * FROM orders WHERE id BETWEEN 10 AND 20 FOR UPDATE;-- 事务 BBEGIN;INSERT INTO orders(id, user_id, status) VALUES (15, 98765, 1);
事务 A 的范围查询会加 Next-Key Lock,覆盖相关记录和间隙。事务 B 想插入 id = 15,就要申请插入意向锁,但这个锁会被事务 A 已持有的 Next-Key Lock 阻塞。
这里要特别区分两个概念:
| 概念 | 它是什么 | 主要作用 |
|---|---|---|
| S 锁 | 锁模式,共享锁 | 允许并发读,阻止写 |
| X 锁 | 锁模式,排他锁 | 修改记录时独占 |
| 插入意向锁 | 特殊 Gap Lock | 让不同位置的并发插入尽量不互相阻塞 |
| Next-Key Lock | Record Lock + Gap Lock | RR 下防止幻读 |
唯一索引检查、外键检查、SELECT ... FOR UPDATE、范围更新等场景,都可能让插入等待。判断一个 INSERT 为什么卡住时,不要只看它自己,还要看是否有其他事务提前锁住了它要进入的记录或间隙。
插入意向锁的核心源码在 storage/innobase/lock/lock0lock.cc:5894 的 lock_rec_insert_check_and_lock()。它会构造 LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION,具体在 storage/innobase/lock/lock0lock.cc:5975。宏 LOCK_INSERT_INTENTION 定义在 storage/innobase/include/lock0lock.h:980。唯一二级索引检查则可以看 storage/innobase/row/row0ins.cc:2071 的 row_ins_scan_sec_index_for_duplicate(),源码注释里说明这里会对可能重复的记录加共享锁。
7. 提交以后,后台还在继续收尾
当客户端收到提交成功时,说明事务层面的持久性已经由日志保证了。
但这并不代表所有脏页已经写回磁盘。
提交之后,后台线程还会继续做几件事:
- 根据 checkpoint 推进情况,把脏数据页刷回磁盘;
- 把脏的 Undo 页、Change Buffer 页等内部页刷盘;
- 在没有活跃快照需要旧版本后,由 purge 线程清理 Undo 记录;
- 在合适时机继续做 Change Buffer merge。
这也是 InnoDB 性能设计里很重要的一点:
前台事务尽量只做必须同步完成的事,能延迟、能合并、能后台处理的工作,都尽量放到后面。
后台线程里能直接看到这些收尾动作:storage/innobase/srv/srv0srv.cc:2136 和 storage/innobase/srv/srv0srv.cc:2229 都会触发 ibuf_merge_in_background(...);storage/innobase/srv/srv0srv.cc:2322 附近会推进 checkpoint。Redo crash recovery 的入口可以看 storage/innobase/log/log0recv.cc:4040 的 recv_recovery_from_checkpoint_start()。
8. 把这条 INSERT 串起来
现在回到开头的 SQL:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
完整链路可以这样理解:
- 客户端把 SQL 发给 MySQL Server;
- Server 层完成连接、权限、解析、预处理和执行器调度;
- 执行器调用 InnoDB 的写入接口;
- InnoDB 生成自增主键值;
- 根据主键定位聚簇索引叶子页,顺序插入时大概率命中最右页;
- 写入 Undo 记录,并把行记录上的
DB_ROLL_PTR指向这条 Undo; - 修改 Buffer Pool 中的数据页,并写 Redo Log 保护 Undo 页、数据页和索引页的物理修改;
- 维护二级索引,非唯一二级索引可能进入 Change Buffer;
- 刷脏页时遵守 WAL:数据页可以晚于提交落盘,也可以早于提交落盘,但不能早于对应 Redo 落盘;
- 提交时执行 Redo prepare、写 Binlog、Redo commit;
- 提交成功后,后台线程继续刷脏页、合并 Change Buffer、清理 Undo。
如果只记一句话,我会这样概括:
InnoDB 的插入性能,来自“前台用日志保证正确性,后台再慢慢整理数据页”。
Redo Log 把随机数据页写入变成顺序日志写入;Change Buffer 把非唯一二级索引的随机读延迟合并;自增主键让聚簇索引写入尽量落在最右侧;两阶段提交则保证 InnoDB 事务和 Server 层 Binlog 不会各走各的。
这套机制最后共同服务于一个目标:在保证 ACID 的前提下,让一条普通的 INSERT 尽可能快地返回。
9. 源码对照表
下面这张表可以作为阅读 MySQL 5.7.44 源码时的路线图。路径均相对源码根目录。
| 文章里的环节 | 源码位置 | 作用 | ||
|---|---|---|---|---|
| SQL 解析入口 | sql/sql_parse.cc:1486、sql/sql_parse.cc:1492 |
初始化 parser 并进入 mysql_parse() |
||
| SQL 执行分发 | sql/sql_parse.cc:2455 mysql_execute_command() |
根据解析结果分发到具体语句处理逻辑 | ||
| 连接认证 | sql/sql_connect.cc:692、sql/auth/sql_authentication.cc:2188 |
连接阶段调用 acl_authenticate() |
||
| 授权缓存加载 | sql/auth/sql_auth_cache.cc:1486、sql/auth/sql_auth_cache.cc:1512 |
从 mysql.user 读取账号和认证信息 |
||
| Grant 表列表 | sql/auth/sql_user_table.cc:2103 |
user/db/tables_priv/columns_priv/procs_priv/proxies_priv |
||
| 表权限检查 | sql/auth/sql_authorization.cc:1007、sql/auth/sql_authorization.cc:2128 |
检查库表权限和 grant 信息 | ||
| 表定义缓存 | sql/sql_base.cc:435、sql/sql_base.cc:670 |
table_def_cache 和 get_table_share() |
||
读取 .frm |
sql/table.cc:668、sql/table.cc:694、sql/table.cc:709 |
缓存未命中时读取 Server 层表定义 | ||
.frm 中的引擎类型 |
sql/table.cc:1118、sql/table.cc:1712、sql/table.cc:1954 |
从 .frm 解析 legacy db type 或引擎名 |
||
| 根据引擎创建 handler | sql/table.cc:2300、sql/table.cc:3136、sql/handler.cc:653 |
根据 TABLE_SHARE::db_type() 创建具体引擎 handler |
||
| InnoDB 内部字典表 | storage/innobase/dict/dict0load.cc:62 |
SYS_TABLES、SYS_INDEXES、SYS_COLUMNS 等系统表 |
||
| InnoDB 字典加载 | storage/innobase/dict/dict0load.cc:102、storage/innobase/dict/dict0load.cc:1549、storage/innobase/dict/dict0load.cc:2233 |
从 SYS_* 记录加载表、列、索引定义 |
||
| SQL 层 INSERT 入口 | sql/sql_insert.cc:428 Sql_cmd_insert::mysql_insert() |
处理 INSERT 语句的主入口 | ||
| INSERT 打开目标表 | sql/sql_insert.cc:471 open_tables_for_query() |
打开目标表并准备后续字段解析 | ||
| INSERT 字段解析 | sql/sql_insert.cc:177、sql/sql_insert.cc:183 |
在目标表范围内解析显式字段列表 | ||
| 写入一行记录 | sql/sql_insert.cc:1538、sql/sql_insert.cc:1895 |
调用 table->file->ha_write_row(...) |
||
| Handler 统一入口 | sql/handler.cc:8153 handler::ha_write_row() |
进入存储引擎虚函数 write_row() |
||
| InnoDB 写入入口 | storage/innobase/handler/ha_innodb.cc:7507 ha_innobase::write_row() |
InnoDB 接管写入流程 | ||
| THD 到 InnoDB 事务 | storage/innobase/handler/ha_innodb.cc:1728、storage/innobase/handler/ha_innodb.cc:2662 |
从当前连接取得或创建 trx_t |
||
| 引擎注册到事务 | sql/handler.cc:1270、sql/handler.cc:1370、storage/innobase/handler/ha_innodb.cc:2941 |
把 InnoDB 注册进 Server 层事务上下文 | ||
| 自增值生成 | storage/innobase/handler/ha_innodb.cc:16757 get_auto_increment() |
计算和预留 AUTO_INCREMENT 值 | ||
| 自增锁 | storage/innobase/handler/ha_innodb.cc:7388 innobase_lock_autoinc() |
根据锁模式处理 AUTO-INC 锁 | ||
| InnoDB 插入图入口 | storage/innobase/row/row0mysql.cc:1856 row_insert_for_mysql() |
从 MySQL record 转入 InnoDB row insert | ||
| 插入执行节点 | storage/innobase/row/row0ins.cc:3795 row_ins_step() |
执行 InnoDB insert graph | ||
| 遍历索引写入 | storage/innobase/row/row0ins.cc:3750 row_ins() |
依次写聚簇索引和二级索引 | ||
| 聚簇/二级索引分流 | storage/innobase/row/row0ins.cc:3451 row_ins_index_entry() |
判断写聚簇索引还是二级索引 | ||
| 聚簇索引插入 | storage/innobase/row/row0ins.cc:2480 row_ins_clust_index_entry_low() |
定位并插入聚簇索引记录 | ||
| 二级索引插入 | storage/innobase/row/row0ins.cc:3370 row_ins_sec_index_entry() |
写入二级索引项 | ||
| 唯一二级索引检查 | storage/innobase/row/row0ins.cc:2071 row_ins_scan_sec_index_for_duplicate() |
扫描可能重复项并加 S 锁 | ||
| B+ 树乐观插入 | storage/innobase/btr/btr0cur.cc:3042 btr_cur_optimistic_insert() |
页空间足够时直接插入 | ||
| B+ 树悲观插入 | storage/innobase/btr/btr0cur.cc:3320 btr_cur_pessimistic_insert() |
乐观插入失败后处理页分裂 | ||
| 页分裂 | storage/innobase/btr/btr0btr.cc:2514 btr_page_split_and_insert() |
拆分 B+ 树页并插入新记录 | ||
| 顺序右分裂判断 | storage/innobase/btr/btr0btr.cc:1833 btr_page_get_split_rec_to_right() |
判断连续向右插入时的分裂点 | ||
| 页内 last insert 快捷路径 | storage/innobase/page/page0cur.cc:91 page_cur_try_search_shortcut() |
基于 PAGE_LAST_INSERT 尝试快速定位 |
||
| 更新 last insert 信息 | storage/innobase/page/page0cur.cc:1472 |
更新 PAGE_LAST_INSERT、PAGE_DIRECTION |
||
| 插入前加锁和写 Undo | storage/innobase/btr/btr0cur.cc:2939 btr_cur_ins_lock_and_undo() |
检查插入锁并生成 Undo | ||
| 行记录隐藏事务字段 | storage/innobase/include/data0type.h:169、storage/innobase/include/data0type.h:172 |
DB_TRX_ID 和 DB_ROLL_PTR 的内部类型定义 |
||
| Undo 记录生成 | storage/innobase/trx/trx0rec.cc:1844 trx_undo_report_row_operation() |
写入 insert/update undo | ||
| Insert Undo 类型 | storage/innobase/include/trx0rec.h:364 |
TRX_UNDO_INSERT_REC 表示新插入聚簇索引记录 |
||
| Roll Pointer 写入 | storage/innobase/btr/btr0cur.cc:2981、storage/innobase/btr/btr0cur.cc:2997、storage/innobase/trx/trx0rec.cc:2049 |
生成 Undo 后把回滚指针写入行记录 | ||
| Change Buffer 触发 | storage/innobase/btr/btr0cur.cc:1095、storage/innobase/btr/btr0cur.cc:1131 |
目标页不在 Buffer Pool 时尝试 ibuf | ||
| Change Buffer 写入 | storage/innobase/ibuf/ibuf0ibuf.cc:3686 ibuf_insert() |
把二级索引变更写入 Change Buffer | ||
| Change Buffer 合并 | storage/innobase/ibuf/ibuf0ibuf.cc:4426 ibuf_merge_or_delete_for_page() |
目标页读入时合并 buffered changes | ||
| 后台 ibuf merge | storage/innobase/srv/srv0srv.cc:2136、storage/innobase/srv/srv0srv.cc:2229 |
后台线程主动合并 Change Buffer | ||
| 插入意向锁 | storage/innobase/lock/lock0lock.cc:5894 lock_rec_insert_check_and_lock() |
检查间隙锁冲突并申请插入意向锁 | ||
| 插入意向锁标记 | storage/innobase/lock/lock0lock.cc:5975、storage/innobase/include/lock0lock.h:980 |
`LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION` |
| Prepare 阶段 | sql/handler.cc:2338 ha_prepare_low() |
调用存储引擎 prepare | ||
| Binlog 事务缓存 | sql/binlog.cc:865、sql/binlog.cc:1295、sql/binlog.cc:1634 |
管理事务型 binlog cache、写 event、提交时 flush | ||
| Binlog prepare | sql/binlog.cc:8580 MYSQL_BIN_LOG::prepare() |
进入 binlog 事务协调 | ||
| Binlog group commit | sql/binlog.cc:9520 MYSQL_BIN_LOG::ordered_commit() |
flush、sync、commit 三阶段 | ||
| InnoDB commit | storage/innobase/trx/trx0trx.cc:2409 trx_commit_for_mysql() |
InnoDB 事务提交入口 | ||
| 脏页刷盘前刷 Redo | storage/innobase/buf/buf0flu.cc:1055、storage/innobase/buf/buf0flu.cc:1070 |
先把 Redo 写到页最新 LSN,再写数据页 | ||
| Redo recovery | storage/innobase/log/log0recv.cc:4040 recv_recovery_from_checkpoint_start() |
从 checkpoint 开始重放 Redo |