Many MySQL articles explain the connector, parser, optimizer, Undo Log, Redo Log, Binlog, Change Buffer, and locks one by one. Each concept is not hard by itself, but once they are placed together, they can easily turn into a scattered pile of knowledge cards.
A better way to read the system is to hold on to one SQL statement, then follow the path it takes inside MySQL.
This article uses the following statement as the main thread:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
Source version note: source references in this article are based on MySQL
mysql-5.7.44, which is the current checkout of your local source tree at/Users/liuliqiang/src/cpp/github.com/mysql/mysql-server. Paths in the article are relative to the MySQL source root, for examplesql/sql_insert.cc:428.
It looks like a simple insert into the orders table, but InnoDB actually needs to do several things:
- The Server layer must parse the SQL and turn it into a storage engine call.
- InnoDB must find the B+ tree leaf page where the row should be inserted.
- Before writing, it must prepare rollback information; after writing, it must make the change crash recoverable.
- Secondary indexes may cause extra random IO, or may be buffered by the Change Buffer.
- Finally, Redo Log and Binlog must be coordinated through two-phase commit so that transactions and replication stay consistent.
Start with the full picture.
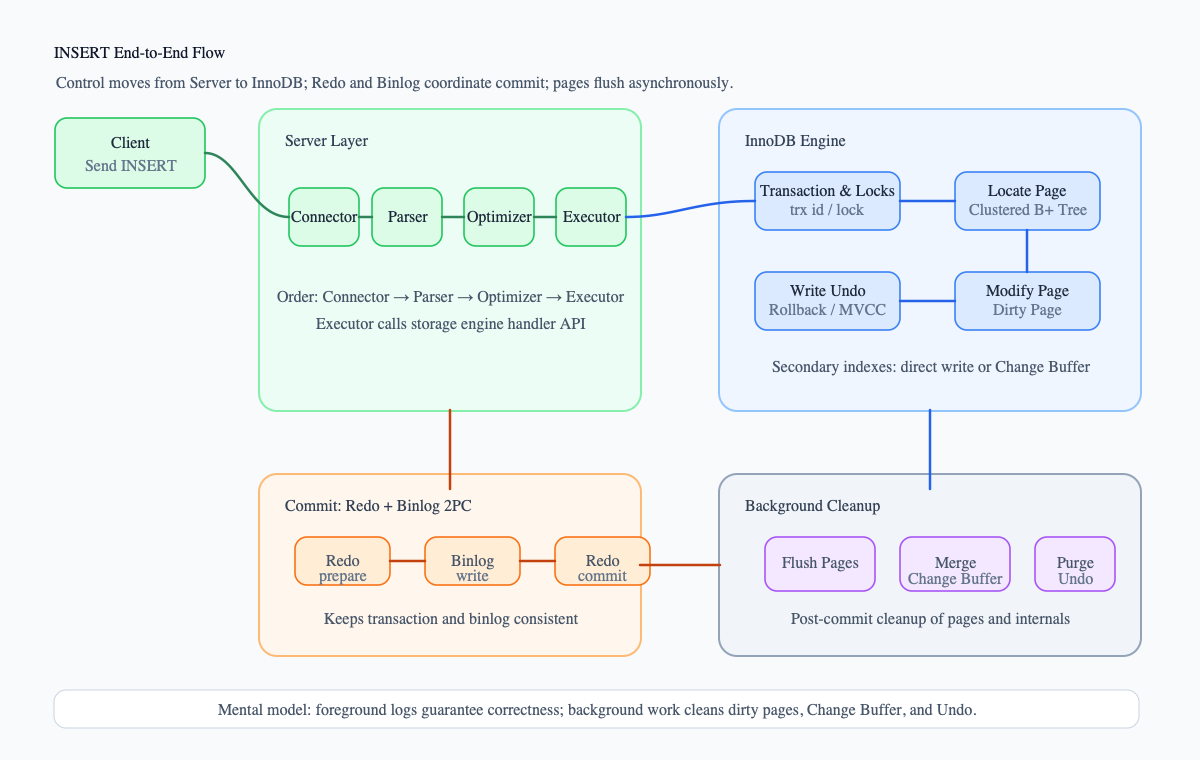
The most important part of the diagram is not every individual box, but the direction in which control moves:
SQL first goes through the Server layer. The actual data write happens inside InnoDB. Transaction commit is coordinated through Redo Log and Binlog. Data pages are eventually flushed back to disk by background threads.
1. Server Layer: Turning SQL into an Engine Call
After the client sends the INSERT, it first enters the MySQL Server layer.
This layer does not directly modify InnoDB data pages. Its main job is to turn SQL into a concrete execution action.
The rough path is:
Client-> Connector-> Parser-> Preprocessor-> Optimizer-> Executor-> InnoDB storage engine
The connector handles authentication, permissions, connection state, and thread context. The parser performs lexical and syntax analysis, then turns the SQL into a parse tree. The preprocessing phase checks whether tables, columns, permissions, and related information are valid.
For an INSERT, the optimizer has much less room to work than it does for a complex SELECT. It mainly confirms the target table, target columns, write path, and the handling path for statements such as ON DUPLICATE KEY UPDATE.
Finally, the executor calls the handler interface exposed by InnoDB. You can think of it like this:
Server layer: This row should be written into the orders table.InnoDB: Got it. I will handle the real data structure changes and transaction guarantees.
In the MySQL 5.7 source code, the INSERT entry point is Sql_cmd_insert::mysql_insert() at sql/sql_insert.cc:428. The place where one row is handed to the storage engine is inside write_record(), which calls table->file->ha_write_row(...). The normal insert path is around sql/sql_insert.cc:1895, and the duplicate-key handling path is around sql/sql_insert.cc:1538.
ha_write_row() is the unified Server-layer handler entry point. It is defined at sql/handler.cc:8153, and eventually calls the concrete storage engine implementation of write_row(). If the table uses InnoDB, execution enters ha_innobase::write_row() at storage/innobase/handler/ha_innodb.cc:7507.
From this point on, the problem enters the core of InnoDB.
Which Metadata Does the Server Layer Read?
There is an easy point to mix up here: the connector, parser, and optimizer do not all read the same “table metadata”.
In MySQL 5.7, table structure is mainly split into two layers:
datadir/db_name/orders.frm Server-layer table definitionorders.ibd InnoDB data pages and index pagesibdata1 InnoDB system tablespace, containing SYS_TABLES / SYS_COLUMNS / SYS_INDEXES and other internal dictionary tables
The .frm file is the Server layer’s entry point for understanding a table definition. It stores columns, types, indexes, table options, partition information, and the storage engine used by the table. InnoDB also stores table, column, index, and tablespace information in its own internal data dictionary, such as SYS_TABLES, SYS_COLUMNS, SYS_INDEXES, SYS_FIELDS, and SYS_TABLESPACES.
So the stages can be separated like this:
| Stage | What it reads | Notes |
|---|---|---|
| Connector | ACL permission cache, loaded from grant tables such as mysql.user, mysql.db, and mysql.tables_priv |
Handles authentication and permission context. It does not know the storage engine of the target business table. |
| Parser | SQL text | Parses INSERT INTO orders ... into syntax structures and table references, but does not really open the orders table. |
| Preprocessing / table open | TABLE_SHARE, usually from table_def_cache; if the cache misses, it reads .frm |
Confirms that the table, columns, and field list are valid, and obtains the table engine from .frm. |
| Optimizer | Opened TABLE / TABLE_SHARE, plus statistics exposed by the handler |
Ordinary INSERT ... VALUES has little optimization space; the SELECT part of INSERT ... SELECT goes through fuller optimization. |
| Executor | Handler attached to TABLE |
Creates the concrete handler from TABLE_SHARE::db_type(), for example InnoDB’s ha_innobase. |
In other words, the connector does not know at connection time whether orders is InnoDB or MyISAM. That information is filled into TABLE_SHARE when the table definition is opened, either from table_def_cache or from the .frm file.
In the source code, the connection authentication entry is at sql/sql_connect.cc:692, which calls acl_authenticate(...). The authorization cache comes from tables such as mysql.user; the loading logic is around sql/auth/sql_auth_cache.cc:1486. The SQL parsing entry is between sql/sql_parse.cc:1486 and sql/sql_parse.cc:1492. The target table for INSERT is opened at open_tables_for_query(...) in sql/sql_insert.cc:471.
When opening a table, the Server layer first checks table_def_cache. If it misses, open_table_def() at sql/table.cc:694 reads the .frm file and fills a TABLE_SHARE. The storage engine type comes from the db type field in .frm; related parsing can be found at sql/table.cc:1118, sql/table.cc:1712, and sql/table.cc:1954. The concrete handler is then created according to share->db_type(), with entry points at sql/table.cc:2300 and sql/handler.cc:653.
This is also an important difference between MySQL 5.7 and 8.0: 5.7 still uses the two-layer .frm + InnoDB SYS_* metadata model, while 8.0 removes .frm and replaces it with a transactional data dictionary.
2. InnoDB First Finds the Target Page
In InnoDB, the table data itself is a B+ tree organized by primary key. This is also called the clustered index.
If orders uses an auto-increment primary key, InnoDB must first obtain a new primary key value before the real insert, for example:
id = 10000001
It then uses this primary key value to find the target leaf page in the clustered index B+ tree.
Why Are Auto-Increment Primary Keys Fast to Insert?
Auto-increment primary keys have a major advantage: new records usually land on the rightmost leaf page of the B+ tree.
InnoDB caches the previous insert position. As long as the new primary key keeps increasing, and the previous page can still accept new records, InnoDB can append directly to the end of that leaf page instead of searching from the root every time.
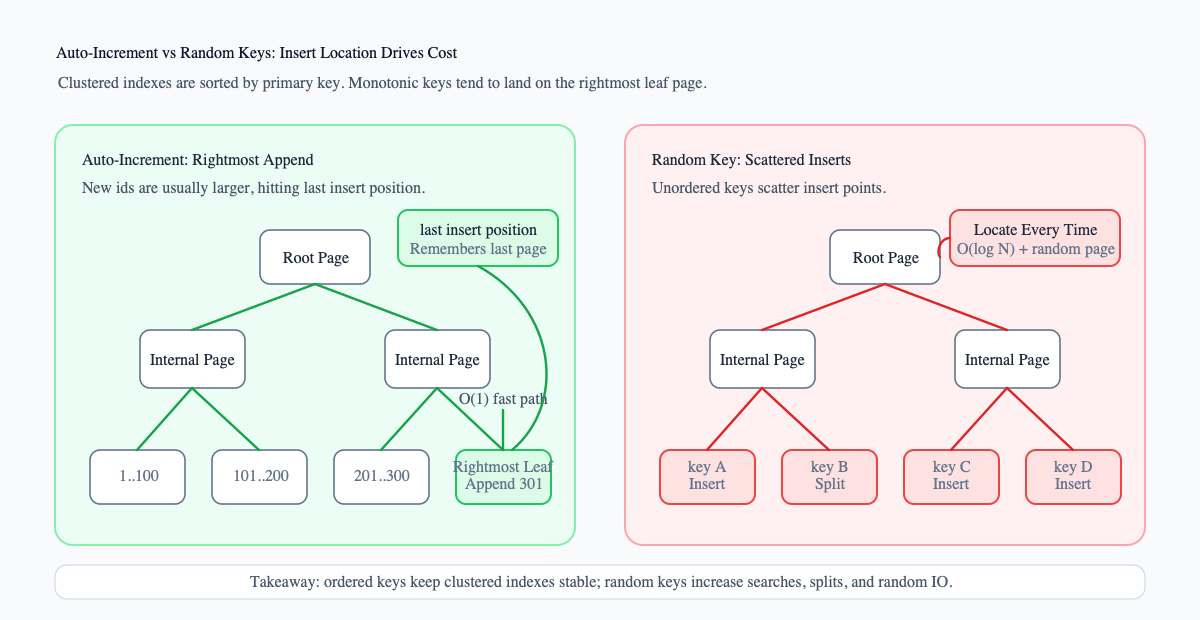
This part has two layers in the source code. Auto-increment value generation happens in ha_innobase::get_auto_increment() at storage/innobase/handler/ha_innodb.cc:16757. Auto-increment locking is handled in ha_innobase::innobase_lock_autoinc() at storage/innobase/handler/ha_innodb.cc:7388. The page-level “last insert” shortcut can be found in page_cur_try_search_shortcut() at storage/innobase/page/page0cur.cc:91, and the logic that updates PAGE_LAST_INSERT and PAGE_DIRECTION is around storage/innobase/page/page0cur.cc:1472.
This is the fundamental reason auto-increment primary keys work well for high-throughput inserts:
- The positioning path is short, and often hits the previous insert page.
- When a page becomes full, it is more likely to split to the right, so the old page does not need to move half of its records.
- Data pages are more compact, and disk writes are closer to sequential writes.
Random primary keys are different. Values such as UUID v4 are not monotonic, so insert positions scatter across the B+ tree. Each write may hit a different leaf page, and page splits are more likely to happen in the middle.
A quick comparison:
| Dimension | Auto-increment primary key | UUID / random primary key |
|---|---|---|
| Insert position | Right side of the B+ tree | Scattered across leaf pages |
| Positioning path | Often hits previous insert position | Usually needs a full search |
| Page split | Often right split | More likely middle split |
| Page fill factor | Higher | More fragmentation |
| IO pattern | Closer to sequential write | More random reads and writes |
This is why many business tables prefer auto-increment IDs, Snowflake IDs, or other monotonic or mostly monotonic primary keys over fully random UUIDs.
Page split code can be found in btr_page_split_and_insert() at storage/innobase/btr/btr0btr.cc:2514. btr_page_get_split_rec_to_right() at storage/innobase/btr/btr0btr.cc:1833 specifically decides the split point for continuous right-side inserts, and the source comment explicitly mentions sequential inserts.
3. The Real Modification Is Not “One Row”, but a Set of Pages
After finding the clustered-index leaf page, InnoDB does not simply put one row into the page and call it done.
One INSERT usually affects these objects:
- Clustered index data page: stores the full row record.
- Undo page: stores the rollback information.
- Redo Log Buffer: records physical modifications for crash recovery.
- Secondary index pages: one index entry must be inserted into each secondary index.
- Change Buffer: if a non-unique secondary index target page is not in memory, the change may be buffered here.
- Transaction system pages and lock structures: maintain transaction IDs, rollback segments, and lock waits.
Most of these pages first enter the Buffer Pool. After being modified, they are marked as dirty pages, but they are not immediately written back to disk.
This point is critical: a successful transaction commit does not mean the data page has already been flushed to disk.
What InnoDB really relies on is WAL: write the log first, then flush data pages later.
The internal insert path continues into row_insert_for_mysql() at storage/innobase/row/row0mysql.cc:1856, then into row_ins_step() at storage/innobase/row/row0ins.cc:3795. row_ins() iterates over the table indexes and inserts one index entry at a time; the key loop is around storage/innobase/row/row0ins.cc:3750.
4. Redo, Undo, and Binlog: Three Tools for Three Problems
This is where many concepts get mixed together.
Start with one sentence:
- Undo Log answers: can the transaction roll back, and can old versions be read?
- Redo Log answers: can committed data be recovered after a crash?
- Binlog answers: can replication and point-in-time recovery replay this logical change?
They are not the same kind of log.
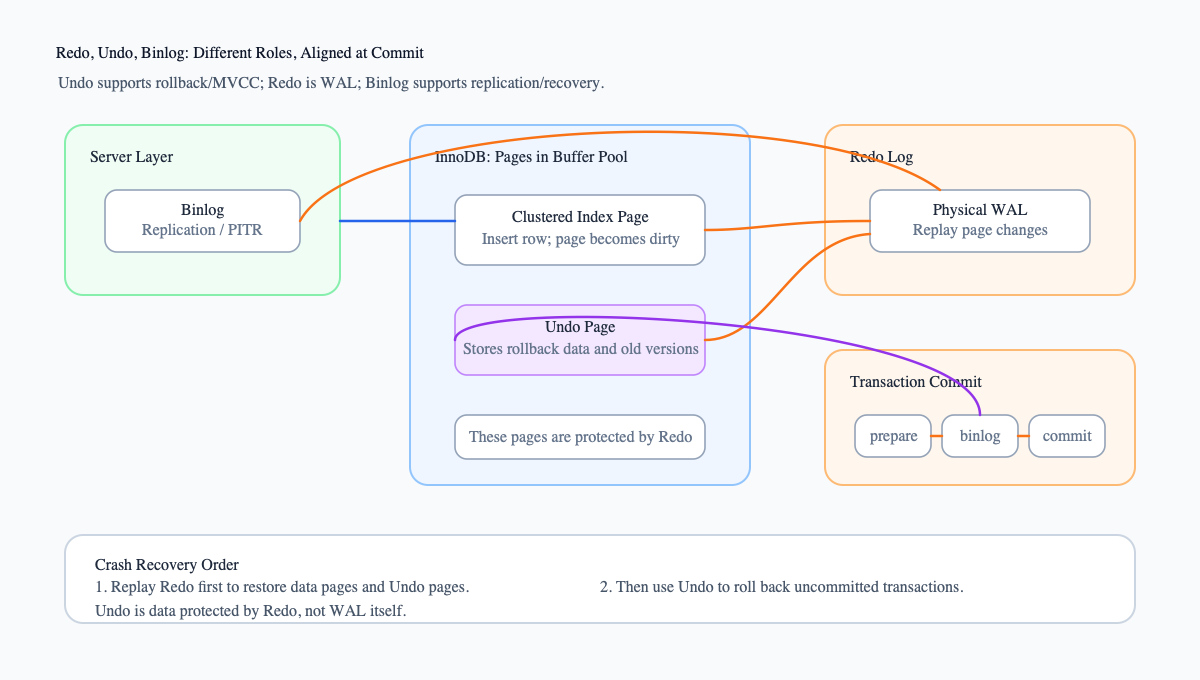
What Do the Three Logs Look Like for One INSERT?
Continue with the same SQL:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
Assume the generated auto-increment primary key is:
id = 10000001
Then the three logs can be understood with the following conceptual samples. These are not byte-for-byte contents from MySQL files. Redo Log and Undo Log both use internal InnoDB formats; Binlog also depends on binlog_format.
First, Undo Log:
Undo record: TRX_UNDO_INSERT_RECtrx_id: trx_12345table: ordersindex: PRIMARYrow key: id = 10000001action: delete this newly inserted clustered-index record during rollback
For an INSERT, Undo does not need to save an “old value”, because the row did not exist before. Its real purpose is to support this: if the transaction rolls back, InnoDB can use the undo record to delete the inserted record. Later, if a consistent read needs to determine whether this row is visible to a certain ReadView, it also uses the transaction information on the row and the undo chain.
Next, Redo Log:
Redo records:1. Modify an undo pagespace_id = undo tablespacepage_no = undo page 42op = write TRX_UNDO_INSERT_REC2. Modify a clustered-index leaf pagespace_id = tablespace id of orders.ibdpage_no = PRIMARY leaf page 1088op = insert record (id=10000001, user_id=98765, status=1)3. Modify a secondary-index page or Change Buffer pagespace_id = orders.ibd or system tablespacepage_no = idx_user_id leaf page / ibuf pageop = insert secondary index entry (user_id=98765, pk=10000001)
Redo cares about “which page in which tablespace changed, and what physical modification happened”. It is not SQL, and it usually does not describe changes mainly by table name. During crash recovery, InnoDB uses these physical log records to restore data pages, undo pages, and Change Buffer pages to the state they should be in.
Finally, Binlog. Binlog is a Server-layer log mainly used for replication and point-in-time recovery. It records logical changes. Its shape depends on binlog_format.
In statement format, it is close to this:
Query event:schema: mydbsql: INSERT INTO orders (user_id, status) VALUES (98765, 1)
In row format, it is closer to this:
Table_map event:table_id: 256schema: mydbtable: orderscolumns: id, user_id, statusWrite_rows event:after image:id = 10000001user_id = 98765status = 1
So the three logs observe the same write from completely different angles:
| Log | Perspective | What this INSERT roughly records |
|---|---|---|
| Undo Log | Transaction rollback / MVCC | If rolling back, delete the row id=10000001 |
| Redo Log | Physical page recovery | Which data pages, undo pages, index pages, and Change Buffer pages changed |
| Binlog | Replication / PITR | This logical write, or the row after image |
Put together, the path is:
Write Undo: used later for rollbackWrite Redo: used for crash recovery, protecting undo-page and data-page changesWrite Binlog: used for replication and point-in-time recoveryRedo prepare + Binlog + Redo commit: make InnoDB and Binlog agree on the same transaction result
How Does a Transaction Connect the Three Logs?
A transaction is not one isolated step in the flow. It is the context that runs through the entire write path.
At the Server layer, each connection has a THD. The THD contains transaction context and also the Binlog transaction cache. At the InnoDB layer, this connection is bound to a trx_t. InnoDB locks, Undo, transaction ID, and commit state all hang off this trx_t.
You can first picture the relationship like this:
THD / Transaction_ctx-> binlog trx cache-> registered engines: InnoDBInnoDB trx_t-> trx_id-> locks-> undo records-> modified pages protected by redo
When the INSERT is actually written, InnoDB writes the current transaction ID into the hidden clustered-index field DB_TRX_ID, and writes the pointer to the Undo record into DB_ROLL_PTR.
So a newly inserted clustered-index record is not only business fields:
orders clustered recordid = 10000001user_id = 98765status = 1DB_TRX_ID = transaction ID of the current InnoDB trx_tDB_ROLL_PTR = pointer to this insert undo record
These two hidden fields connect the row record to the transaction:
DB_TRX_IDtells who modified this row, and whether it is visible to the current ReadView.DB_ROLL_PTRpoints to the Undo record, supporting rollback and old-version construction.- Redo Log protects the pages modified by this transaction, including data pages, Undo pages, and Change Buffer pages.
- Binlog first enters the transaction cache of the
THD, then coordinates with InnoDB prepare / commit at commit time.
In other words, Undo is the transaction’s way back, Redo is insurance for page modifications, and Binlog is the Server layer’s external record for replication and recovery. At commit time, MySQL must ensure that these three things point to the same final result.
The source path can be mapped as follows: thd_to_trx() at storage/innobase/handler/ha_innodb.cc:1728 gets the InnoDB transaction object from THD; check_trx_exists() at storage/innobase/handler/ha_innodb.cc:2662 creates it when needed; storage/innobase/btr/btr0cur.cc:2981 generates Undo and returns roll_ptr; Binlog transaction cache management can be found in binlog_cache_mngr at sql/binlog.cc:865.
Undo Log Is Not WAL
A common misconception is: Undo Log is also WAL.
A more accurate statement is:
Redo Log is InnoDB’s WAL. Undo Log itself is data protected by Redo Log.
Undo Log lives in undo tablespaces, and is essentially stored in data pages. Writing an undo record modifies an undo page; that modification to the undo page must also be written to Redo Log.
So one INSERT produces at least two kinds of redo:
1. Modify an undo page: write an undo record for rollback2. Modify a data page: write the new row into a clustered-index leaf page
Redo Log protects not only user data pages, but also internal InnoDB pages such as Undo pages and Change Buffer pages.
In the source code, storage/innobase/btr/btr0cur.cc:2981 shows that before inserting into the clustered index, InnoDB calls trx_undo_report_row_operation(...) to generate the Undo record for the insert. The function is defined at storage/innobase/trx/trx0rec.cc:1844, and storage/innobase/trx/trx0rec.cc:1989 calls trx_undo_page_report_insert(...) to write the insert undo record.
Two-Phase Commit Keeps Redo and Binlog Consistent
MySQL must maintain both InnoDB Redo Log and the Server-layer Binlog.
If Redo is written but Binlog is not, the primary can recover by itself, but replicas will not know about this change. If Binlog is written but Redo is not committed, replication and the primary’s actual state may diverge.
So commit uses two-phase commit:
1. Redo Log enters prepare state2. Server layer writes Binlog3. Redo Log changes to commit state
After a crash, MySQL can use the states of Redo and Binlog to decide whether the transaction should be committed or rolled back.
A common “safe” production configuration is:
innodb_flush_log_at_trx_commit = 1sync_binlog = 1
The first controls whether Redo Log is flushed at every transaction commit. The second controls whether Binlog is flushed at every transaction commit. The so-called “double 1” setting aims for crash safety, at the cost of more expensive fsyncs.
The Server-layer entry for two-phase commit can be found in ha_prepare_low() at sql/handler.cc:2338, and in MYSQL_BIN_LOG::prepare() at sql/binlog.cc:8580. The main Binlog group commit flow is MYSQL_BIN_LOG::ordered_commit() at sql/binlog.cc:9520, where you can see the flush binlog, sync binlog, and commit storage engine stages. On the InnoDB side, the final transaction commit entry is trx_commit_for_mysql() at storage/innobase/trx/trx0trx.cc:2409.
Flush Order: Data Pages May Reach Disk Before Commit, but Not Before Redo
There is another point that is easy to get stuck on: transaction commit, Redo flush, and data-page flush are not the same thing.
InnoDB allows data pages modified by uncommitted transactions to be flushed to disk early. If the transaction later rolls back, or if InnoDB discovers after a crash that the transaction was not committed, it can still use Undo to undo those changes.
But InnoDB does not allow a data page to be flushed before its corresponding Redo is flushed. Once the data page has been written into .ibd, but the Redo describing that page modification has not reached disk, crash recovery can no longer reliably determine the state of that page modification.
So the real rule is:
A data page may reach disk before transaction commit.A data page must not reach disk before its corresponding redo.
You can understand this through four cases:
| Scenario | Allowed? | What happens after a crash |
|---|---|---|
| Redo is on disk, data page is not, transaction committed | Allowed | Redo replays the committed change. |
| Redo is on disk, data page is on disk, transaction not committed | Allowed | Recovery restores the physical state first, then Undo rolls back the uncommitted transaction. |
| Redo is on disk, data page is on disk, transaction committed | Allowed | The data page already contains the change; recovery uses LSN to decide whether replay is still needed. |
| Data page is on disk, but corresponding Redo is not | Not allowed | This breaks WAL. InnoDB avoids this flush order. |
Every dirty page carries the LSN of its newest modification. Before flushing a dirty page, InnoDB first ensures that Redo has been flushed at least up to that LSN, and only then writes the page back to the data file.
In MySQL 5.7 source code, this protection is visible directly: storage/innobase/buf/buf0flu.cc:1055 calls log_write_up_to(bpage->newest_modification, true) before flushing a dirty page, making sure the log reaches the page’s newest modification LSN. Then storage/innobase/buf/buf0flu.cc:1070 writes that LSN into the page header field FIL_PAGE_LSN.
Therefore, WAL does not mean “all data pages must be flushed immediately at commit”. It means:
Whenever a data page is going to reach disk, the Redo it depends on must already have reached disk first.
5. Change Buffer: Delaying Random IO Until Later
If a table has multiple secondary indexes, one INSERT modifies more than the clustered index.
For example, suppose the orders table has a normal secondary index:
KEY idx_user_id (user_id)
When inserting (user_id = 98765, id = 10000001), InnoDB also needs to insert one index entry into the B+ tree for idx_user_id.
The problem is that the secondary index is sorted by user_id, which has nothing to do with the insert order of the auto-increment primary key. The target leaf page is very likely not in the Buffer Pool.
If every secondary index had to immediately read its target page from disk and then modify it, a large number of random reads would drag down write throughput.
The Change Buffer idea is:
If the target page of a non-unique secondary index is not in memory, do not read it immediately. Instead, record “I need to modify this page”. Later, when the page is read into memory because of a query or another write, merge the buffered changes into it.
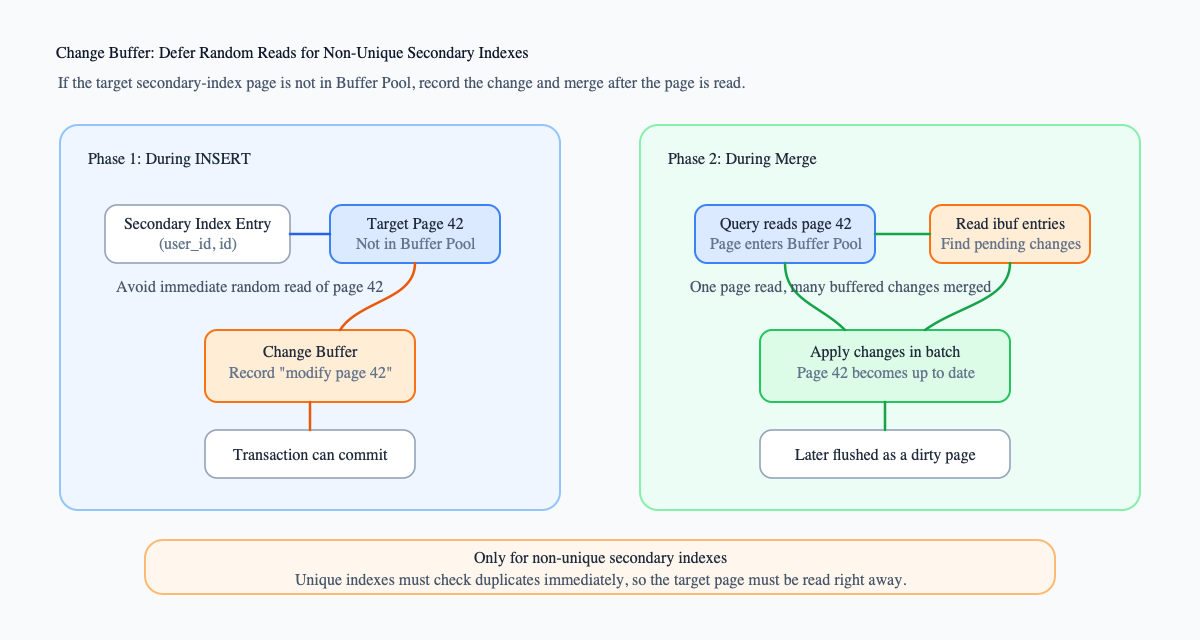
The benefit comes from merging.
Suppose a secondary-index page is hit by 1000 inserts within a period of time:
Without Change Buffer:It may trigger 1000 random reads.With Change Buffer:First record 1000 buffered changes.When the target page is later read, merge them all at once.
This does not reduce the amount of data that must eventually be written. It changes “read a random page immediately” into “delay the work until a later merge opportunity”.
However, Change Buffer has an important restriction: it can only be used for non-unique secondary indexes.
The reason is simple. A unique index must immediately check whether the target key already exists. Since it must check existence, it must read the target leaf page, so the random IO cannot be avoided.
| Index type | Can use Change Buffer? | Reason |
|---|---|---|
| Clustered index | No | The data row itself must be written to the correct position immediately. |
| Unique secondary index | No | Duplicate checking must happen immediately. |
| Non-unique secondary index | Yes | It does not need immediate duplicate checking. |
Change Buffer itself is also a persistent structure and is protected by Redo Log. Therefore, it changes only the performance path, not transactional correctness.
In the source code, the secondary-index insert path is row_ins_sec_index_entry() at storage/innobase/row/row0ins.cc:3370. Around storage/innobase/row/row0ins.cc:2955, InnoDB opens insert-buffering search mode for non-temporary, non-spatial indexes. The logic that decides “if the target page is not in the Buffer Pool, try writing Change Buffer” is between storage/innobase/btr/btr0cur.cc:1095 and storage/innobase/btr/btr0cur.cc:1132; after success, the cursor is marked as BTR_CUR_INSERT_TO_IBUF. The Change Buffer write entry is ibuf_insert() at storage/innobase/ibuf/ibuf0ibuf.cc:3686, and the merge entry is ibuf_merge_or_delete_for_page() at storage/innobase/ibuf/ibuf0ibuf.cc:4426.
6. Locks: Why Do Some INSERT Statements Wait?
Most ordinary inserts do not block each other.
InnoDB has Insert Intention Lock for inserts. It is a special Gap Lock that expresses:
I am going to insert a record into this gap.
If multiple transactions want to insert different values into the same gap, their insert intention locks are compatible with each other. This is what allows concurrent INSERT statements to run.
What usually blocks an insert is a range lock.
For example, under the RR isolation level:
-- Transaction ABEGIN;SELECT * FROM orders WHERE id BETWEEN 10 AND 20 FOR UPDATE;-- Transaction BBEGIN;INSERT INTO orders(id, user_id, status) VALUES (15, 98765, 1);
Transaction A’s range query adds Next-Key Locks that cover the related records and gaps. Transaction B wants to insert id = 15, so it must request an insert intention lock, but that lock is blocked by the Next-Key Lock already held by transaction A.
It is important to distinguish these concepts:
| Concept | What it is | Main purpose |
|---|---|---|
| S lock | Lock mode, shared lock | Allows concurrent reads and blocks writes |
| X lock | Lock mode, exclusive lock | Exclusive access when modifying a record |
| Insert intention lock | Special Gap Lock | Lets concurrent inserts into different positions avoid blocking each other |
| Next-Key Lock | Record Lock + Gap Lock | Prevents phantom reads under RR |
Unique index checks, foreign key checks, SELECT ... FOR UPDATE, range updates, and similar scenarios can all make an insert wait. When diagnosing why an INSERT is stuck, do not only look at the insert itself. Also check whether another transaction has already locked the record or gap that this insert needs to enter.
The core source code for insert intention locks is lock_rec_insert_check_and_lock() at storage/innobase/lock/lock0lock.cc:5894. It constructs LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION, specifically around storage/innobase/lock/lock0lock.cc:5975. The macro LOCK_INSERT_INTENTION is defined at storage/innobase/include/lock0lock.h:980. Unique secondary index checking can be found in row_ins_scan_sec_index_for_duplicate() at storage/innobase/row/row0ins.cc:2071; the source comment explains that shared locks are added to possible duplicate records.
7. After Commit, Background Work Continues
When the client receives a successful commit response, transaction-level durability has already been guaranteed by logs.
But this does not mean all dirty pages have already been written back to disk.
After commit, background threads continue doing several things:
- Flush dirty data pages back to disk according to checkpoint progress.
- Flush dirty Undo pages, Change Buffer pages, and other internal pages.
- Let the purge thread clean Undo records after no active snapshot needs old versions.
- Continue Change Buffer merge at suitable times.
This is an important part of InnoDB’s performance design:
The foreground transaction does only the work that must be completed synchronously. Work that can be delayed, merged, or handled in the background is pushed back whenever possible.
You can see these background tasks in the source code. storage/innobase/srv/srv0srv.cc:2136 and storage/innobase/srv/srv0srv.cc:2229 both trigger ibuf_merge_in_background(...); the checkpoint is advanced around storage/innobase/srv/srv0srv.cc:2322. The Redo crash recovery entry is recv_recovery_from_checkpoint_start() at storage/innobase/log/log0recv.cc:4040.
8. Putting the INSERT Back Together
Now return to the SQL at the beginning:
INSERT INTO orders (user_id, status) VALUES (98765, 1);
The full path can be understood like this:
- The client sends SQL to MySQL Server.
- The Server layer handles connection, permissions, parsing, preprocessing, and executor scheduling.
- The executor calls InnoDB’s write interface.
- InnoDB generates an auto-increment primary key value.
- InnoDB uses the primary key to locate the clustered-index leaf page. For sequential inserts, it is likely to hit the rightmost page.
- InnoDB writes an Undo record, and points the row’s
DB_ROLL_PTRto that Undo record. - InnoDB modifies pages in the Buffer Pool, and writes Redo Log to protect the physical modifications of Undo pages, data pages, and index pages.
- InnoDB maintains secondary indexes. Non-unique secondary indexes may go through Change Buffer.
- Dirty-page flushing follows WAL: a data page may reach disk after commit or before commit, but never before its corresponding Redo reaches disk.
- Commit executes Redo prepare, writes Binlog, then Redo commit.
- After commit succeeds, background threads continue flushing dirty pages, merging Change Buffer, and cleaning Undo.
If you only remember one sentence, I would summarize it like this:
InnoDB insert performance comes from using foreground logs to guarantee correctness, then letting background threads organize data pages later.
Redo Log turns random data-page writes into sequential log writes. Change Buffer delays random reads for non-unique secondary indexes and merges them later. Auto-increment primary keys make clustered-index writes usually land on the right side. Two-phase commit ensures that InnoDB transactions and Server-layer Binlog do not go their separate ways.
All these mechanisms serve one goal: while preserving ACID, make an ordinary INSERT return as quickly as possible.
9. Source Code Map
The following table can be used as a route map when reading the MySQL 5.7.44 source code. Paths are relative to the source root.
| Article topic | Source location | Purpose | ||
|---|---|---|---|---|
| SQL parsing entry | sql/sql_parse.cc:1486, sql/sql_parse.cc:1492 |
Initialize parser and enter mysql_parse() |
||
| SQL execution dispatch | sql/sql_parse.cc:2455 mysql_execute_command() |
Dispatch to specific statement handling logic according to parse result | ||
| Connection authentication | sql/sql_connect.cc:692, sql/auth/sql_authentication.cc:2188 |
Call acl_authenticate() during connection setup |
||
| Authorization cache loading | sql/auth/sql_auth_cache.cc:1486, sql/auth/sql_auth_cache.cc:1512 |
Read account and authentication information from mysql.user |
||
| Grant table list | sql/auth/sql_user_table.cc:2103 |
user/db/tables_priv/columns_priv/procs_priv/proxies_priv |
||
| Table permission check | sql/auth/sql_authorization.cc:1007, sql/auth/sql_authorization.cc:2128 |
Check database/table permissions and grant information | ||
| Table definition cache | sql/sql_base.cc:435, sql/sql_base.cc:670 |
table_def_cache and get_table_share() |
||
Read .frm |
sql/table.cc:668, sql/table.cc:694, sql/table.cc:709 |
Read Server-layer table definition on cache miss | ||
Engine type in .frm |
sql/table.cc:1118, sql/table.cc:1712, sql/table.cc:1954 |
Parse legacy db type or engine name from .frm |
||
| Create handler by engine | sql/table.cc:2300, sql/table.cc:3136, sql/handler.cc:653 |
Create concrete engine handler according to TABLE_SHARE::db_type() |
||
| InnoDB internal dictionary tables | storage/innobase/dict/dict0load.cc:62 |
SYS_TABLES, SYS_INDEXES, SYS_COLUMNS, and other system tables |
||
| InnoDB dictionary loading | storage/innobase/dict/dict0load.cc:102, storage/innobase/dict/dict0load.cc:1549, storage/innobase/dict/dict0load.cc:2233 |
Load table, column, and index definitions from SYS_* records |
||
| SQL-layer INSERT entry | sql/sql_insert.cc:428 Sql_cmd_insert::mysql_insert() |
Main entry for handling INSERT statements | ||
| Open target table for INSERT | sql/sql_insert.cc:471 open_tables_for_query() |
Open target table and prepare later field resolution | ||
| INSERT field resolution | sql/sql_insert.cc:177, sql/sql_insert.cc:183 |
Resolve explicit field list in target table scope | ||
| Write one row | sql/sql_insert.cc:1538, sql/sql_insert.cc:1895 |
Call table->file->ha_write_row(...) |
||
| Unified handler entry | sql/handler.cc:8153 handler::ha_write_row() |
Enter storage engine virtual function write_row() |
||
| InnoDB write entry | storage/innobase/handler/ha_innodb.cc:7507 ha_innobase::write_row() |
InnoDB takes over the write flow | ||
| THD to InnoDB transaction | storage/innobase/handler/ha_innodb.cc:1728, storage/innobase/handler/ha_innodb.cc:2662 |
Get or create trx_t from the current connection |
||
| Engine registration into transaction | sql/handler.cc:1270, sql/handler.cc:1370, storage/innobase/handler/ha_innodb.cc:2941 |
Register InnoDB into the Server-layer transaction context | ||
| Auto-increment value generation | storage/innobase/handler/ha_innodb.cc:16757 get_auto_increment() |
Calculate and reserve AUTO_INCREMENT values | ||
| Auto-increment lock | storage/innobase/handler/ha_innodb.cc:7388 innobase_lock_autoinc() |
Handle AUTO-INC lock according to lock mode | ||
| InnoDB insert graph entry | storage/innobase/row/row0mysql.cc:1856 row_insert_for_mysql() |
Convert MySQL record into InnoDB row insert | ||
| Insert execution node | storage/innobase/row/row0ins.cc:3795 row_ins_step() |
Execute InnoDB insert graph | ||
| Iterate index writes | storage/innobase/row/row0ins.cc:3750 row_ins() |
Insert clustered-index and secondary-index entries one by one | ||
| Clustered / secondary index branch | storage/innobase/row/row0ins.cc:3451 row_ins_index_entry() |
Decide whether to write clustered index or secondary index | ||
| Clustered-index insert | storage/innobase/row/row0ins.cc:2480 row_ins_clust_index_entry_low() |
Locate and insert clustered-index record | ||
| Secondary-index insert | storage/innobase/row/row0ins.cc:3370 row_ins_sec_index_entry() |
Insert secondary-index entry | ||
| Unique secondary-index check | storage/innobase/row/row0ins.cc:2071 row_ins_scan_sec_index_for_duplicate() |
Scan possible duplicates and add S locks | ||
| B+ tree optimistic insert | storage/innobase/btr/btr0cur.cc:3042 btr_cur_optimistic_insert() |
Insert directly when the page has enough space | ||
| B+ tree pessimistic insert | storage/innobase/btr/btr0cur.cc:3320 btr_cur_pessimistic_insert() |
Handle page split after optimistic insert fails | ||
| Page split | storage/innobase/btr/btr0btr.cc:2514 btr_page_split_and_insert() |
Split B+ tree page and insert new record | ||
| Sequential right-split check | storage/innobase/btr/btr0btr.cc:1833 btr_page_get_split_rec_to_right() |
Decide split point for continuous right-side inserts | ||
| Page-level last insert shortcut | storage/innobase/page/page0cur.cc:91 page_cur_try_search_shortcut() |
Try fast positioning based on PAGE_LAST_INSERT |
||
| Update last insert information | storage/innobase/page/page0cur.cc:1472 |
Update PAGE_LAST_INSERT and PAGE_DIRECTION |
||
| Lock and write Undo before insert | storage/innobase/btr/btr0cur.cc:2939 btr_cur_ins_lock_and_undo() |
Check insert lock and generate Undo | ||
| Hidden transaction fields on row | storage/innobase/include/data0type.h:169, storage/innobase/include/data0type.h:172 |
Internal type definitions for DB_TRX_ID and DB_ROLL_PTR |
||
| Undo record generation | storage/innobase/trx/trx0rec.cc:1844 trx_undo_report_row_operation() |
Write insert/update undo | ||
| Insert Undo type | storage/innobase/include/trx0rec.h:364 |
TRX_UNDO_INSERT_REC means a fresh clustered-index insert |
||
| Roll pointer write | storage/innobase/btr/btr0cur.cc:2981, storage/innobase/btr/btr0cur.cc:2997, storage/innobase/trx/trx0rec.cc:2049 |
Generate Undo and write rollback pointer into the row record | ||
| Change Buffer trigger | storage/innobase/btr/btr0cur.cc:1095, storage/innobase/btr/btr0cur.cc:1131 |
Try ibuf when target page is not in Buffer Pool | ||
| Change Buffer write | storage/innobase/ibuf/ibuf0ibuf.cc:3686 ibuf_insert() |
Write secondary-index change into Change Buffer | ||
| Change Buffer merge | storage/innobase/ibuf/ibuf0ibuf.cc:4426 ibuf_merge_or_delete_for_page() |
Merge buffered changes when target page is read | ||
| Background ibuf merge | storage/innobase/srv/srv0srv.cc:2136, storage/innobase/srv/srv0srv.cc:2229 |
Background thread actively merges Change Buffer | ||
| Insert intention lock | storage/innobase/lock/lock0lock.cc:5894 lock_rec_insert_check_and_lock() |
Check gap-lock conflict and request insert intention lock | ||
| Insert intention lock flag | storage/innobase/lock/lock0lock.cc:5975, storage/innobase/include/lock0lock.h:980 |
`LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION` |
| Prepare phase | sql/handler.cc:2338 ha_prepare_low() |
Call storage engine prepare | ||
| Binlog transaction cache | sql/binlog.cc:865, sql/binlog.cc:1295, sql/binlog.cc:1634 |
Manage transactional binlog cache, write events, and flush at commit | ||
| Binlog prepare | sql/binlog.cc:8580 MYSQL_BIN_LOG::prepare() |
Enter binlog transaction coordination | ||
| Binlog group commit | sql/binlog.cc:9520 MYSQL_BIN_LOG::ordered_commit() |
Flush, sync, and commit stages | ||
| InnoDB commit | storage/innobase/trx/trx0trx.cc:2409 trx_commit_for_mysql() |
InnoDB transaction commit entry | ||
| Flush Redo before dirty page | storage/innobase/buf/buf0flu.cc:1055, storage/innobase/buf/buf0flu.cc:1070 |
Write Redo up to the page’s newest LSN before writing the data page | ||
| Redo recovery | storage/innobase/log/log0recv.cc:4040 recv_recovery_from_checkpoint_start() |
Replay Redo from checkpoint |