Why Business Code Is Starting to Look Less Like Business Code
The first major change brought by microservice architecture is that a business system gets split into many services that can be deployed, scaled, and evolved independently. This makes team boundaries clearer and gives the system more elasticity, but it also pushes many previously hidden problems directly onto application developers.
An apparently simple business action like "placing an order" may involve service discovery, service invocation, retries, timeouts, circuit breaking, state storage, event publishing, idempotency, compensation, secrets, configuration, and observability. As the code grows, the business logic itself can become surrounded by distributed-systems details.
So the question Dapr tries to answer is not "is there a new SDK that makes Redis or Kafka easier to call?" It is a more architectural question:
Where should these distributed capabilities live?
If all of them live in business code, applications become heavier and heavier. If all of them live in frameworks, multilingual teams become fragmented by different framework ecosystems. If all of them live in the platform, it becomes hard to express application-level intent. Dapr sits between these boundaries: it tries to move part of the distributed capabilities that applications need out of business code and into a language-neutral, portable runtime layer exposed through standard APIs.
Dapr stands for Distributed Application Runtime. The name already gives away its position: it is not Service Mesh, and it is not a traditional microservice framework. It is a runtime for distributed applications.
From Runtime to Distributed Application Runtime
Runtime is a common concept, but it is also easy to overlook. It refers to a set of supporting capabilities that a program needs in order to run. These capabilities are usually not implemented by business developers themselves, but they affect how the program is executed.
Common examples include:
- Language runtimes: for example, the Go runtime handles goroutine scheduling, garbage collection, memory management, and more.
- Java runtime: the JVM handles bytecode execution, class loading, memory management, and more.
- Container runtime: runc and containerd handle namespaces, cgroups, images, and the container lifecycle.
These runtimes share two traits. First, they live outside the application code. Second, their lifecycle is closely related to application execution. When we write Java code, we do not write the JVM ourselves. When we build a container, we usually do not write runc ourselves.
Once applications enter distributed systems, the supporting capabilities needed at runtime grow significantly. Service calls need to discover target instances and handle failures with retries. State updates may need optimistic locking, transactions, or consistency policies. Event publishing needs delivery guarantees and duplicate-consumption handling. Accessing external systems also involves authentication, connections, rate limiting, and failure isolation.
These capabilities are not the business itself, but the business cannot run without them. This is where the abstraction of a Distributed Application Runtime comes in: move the common capabilities required by distributed applications into a runtime outside the application.
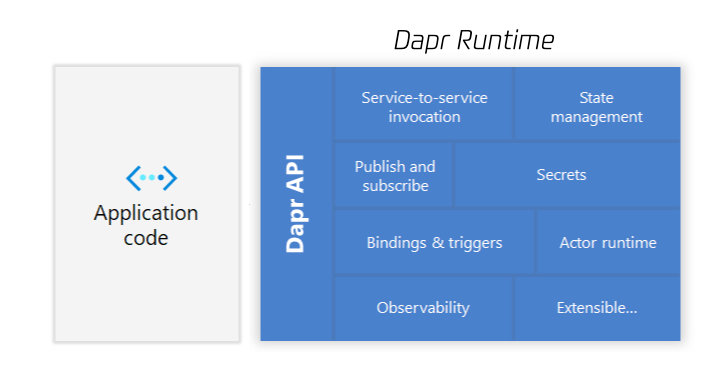
This is where Dapr's innovation lies. It is not simply wrapping several middleware clients. Instead, it tries to abstract distributed capabilities such as service invocation, state, events, external bindings, workflows, configuration, and secrets into a set of standard APIs, so applications can consume these capabilities in a unified way.
Multi Runtime: Where Should Distributed Capabilities Live?
Before understanding Dapr, it helps to look at the idea of Multi Runtime.
Multi Runtime was proposed by Bilgin Ibryam. It is not Dapr's official design document, but it is a useful lens for explaining why projects like Dapr appear. This view argues that the capabilities required by modern distributed applications can roughly be grouped into several categories:
- Lifecycle: deployment, health checks, scaling, configuration management.
- Networking: service discovery, load balancing, retries, circuit breaking, secure communication.
- State: state reads and writes, consistency, concurrency control, caching, idempotency.
- Binding: integration with external systems, messaging systems, cloud services, and event sources.
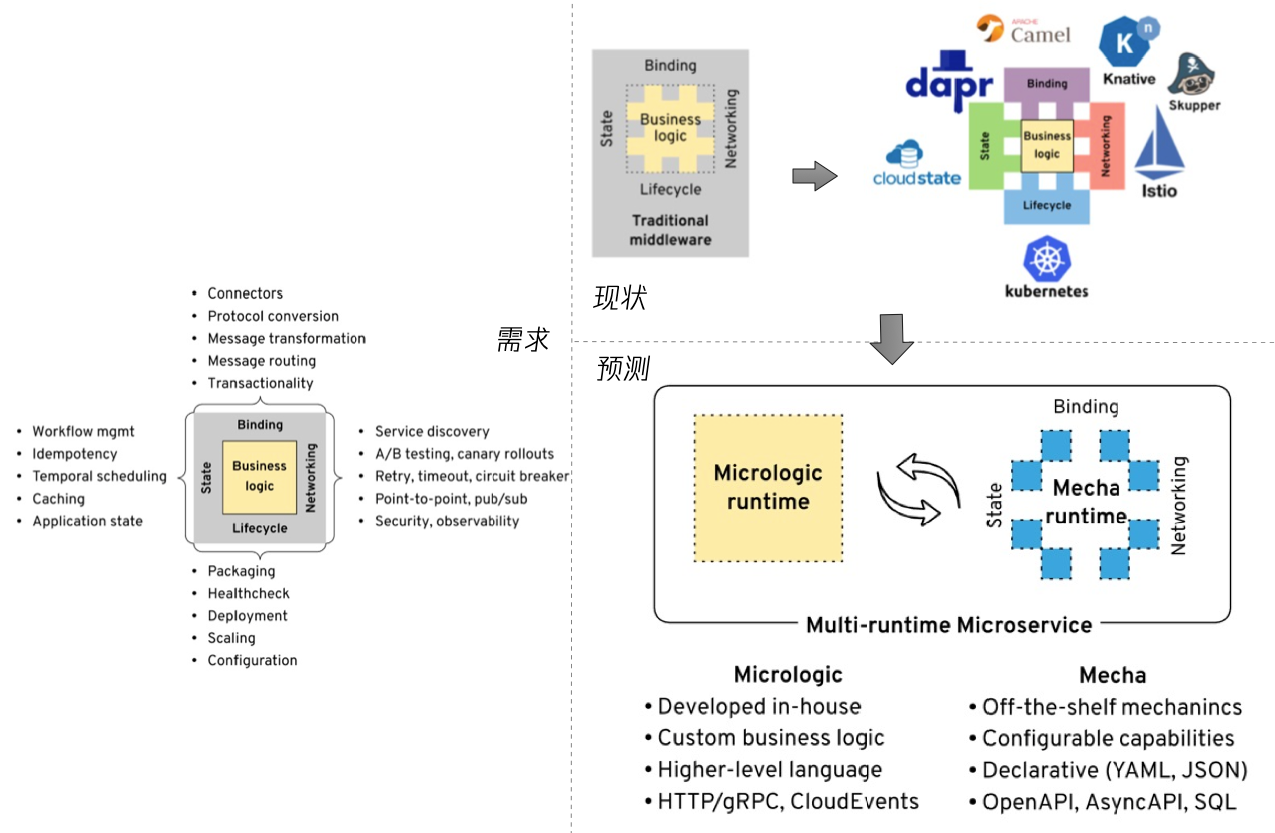
In traditional applications, many of these capabilities were scattered across business code or shared libraries. Later, part of the lifecycle layer was absorbed by infrastructure platforms such as Kubernetes, and part of the service-to-service communication layer was absorbed by Service Mesh. But state, events, external-system integration, and application-level orchestration can still easily fall back into application code.
Dapr's value is that it fills this gap: Kubernetes manages application lifecycle, Service Mesh manages service-to-service traffic, and Dapr tries to manage how applications consume distributed capabilities.
From this perspective, Dapr did not appear out of nowhere. It is a product of further layering in cloud-native architecture. The underlying trend is that more non-business capabilities are being moved out of application code: first into frameworks and SDKs, then into platforms and runtimes.
Dapr's Core Abstraction: Turning Distributed Capabilities into Standard APIs
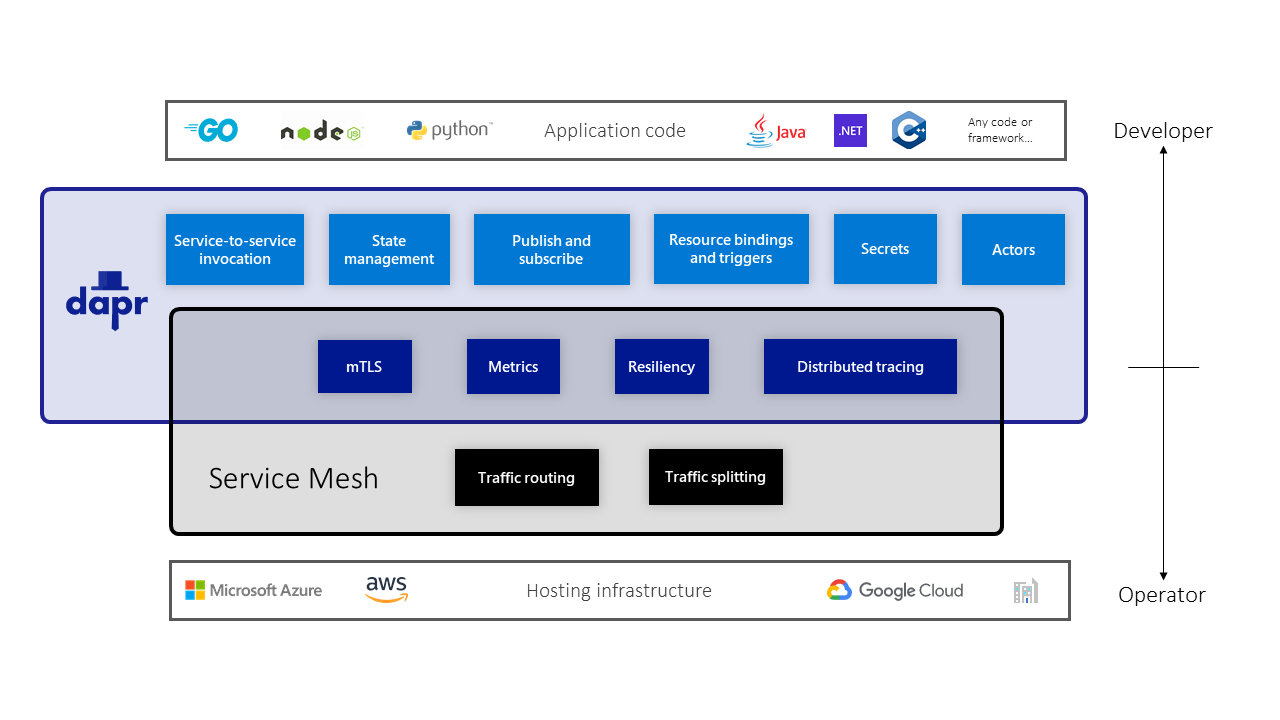
Dapr's design can be understood through four keywords: API, Building Blocks, Components, and Sidecar.
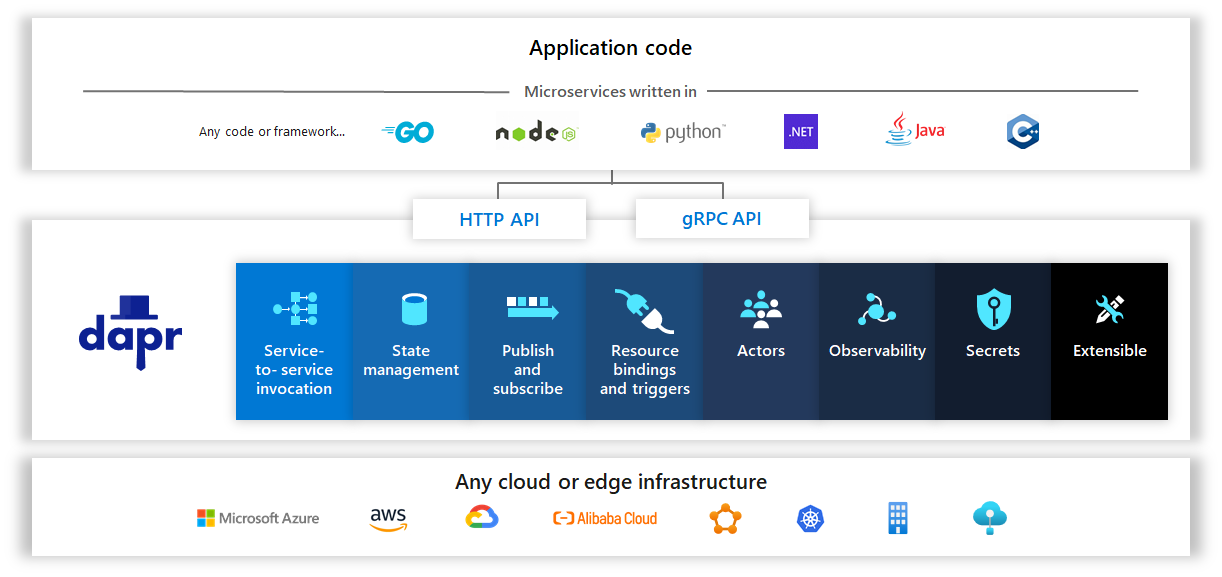
API is the entry point seen by the application. Applications call Dapr APIs over HTTP or gRPC instead of directly depending on Redis, Kafka, MySQL, cloud-provider SDKs, or a specific language framework. Dapr SDKs are only language-friendly wrappers around these APIs.
Building Blocks are capability abstractions. Dapr abstracts common distributed capabilities into modules such as service invocation, publish/subscribe, state management, bindings, Actors, Workflow, Secrets, Configuration, Distributed Lock, Cryptography, Jobs, and Conversation. This should not be read as a "the more features the better" menu. The important point is that Dapr organizes common distributed capabilities into composable application primitives. Conversation, in particular, is more oriented toward AI/LLM scenarios and is still a newer abstraction, so it is better understood as a trend rather than being placed on the same level as foundational capabilities such as state, messaging, and service invocation.
Components are concrete implementations. For state management, the underlying implementation can be Redis, PostgreSQL, MongoDB, a cloud database, or something else. For Pub/Sub, the underlying implementation can be Kafka, RabbitMQ, Redis Streams, or a cloud messaging service. The application faces the Dapr API, while Dapr uses Components to connect to concrete infrastructure.
Sidecar is the runtime form. Dapr capabilities do not run inside the business process. They are exposed by an independent daprd sidecar. The application communicates with the sidecar over local HTTP/gRPC, and the sidecar then accesses other services or external components.
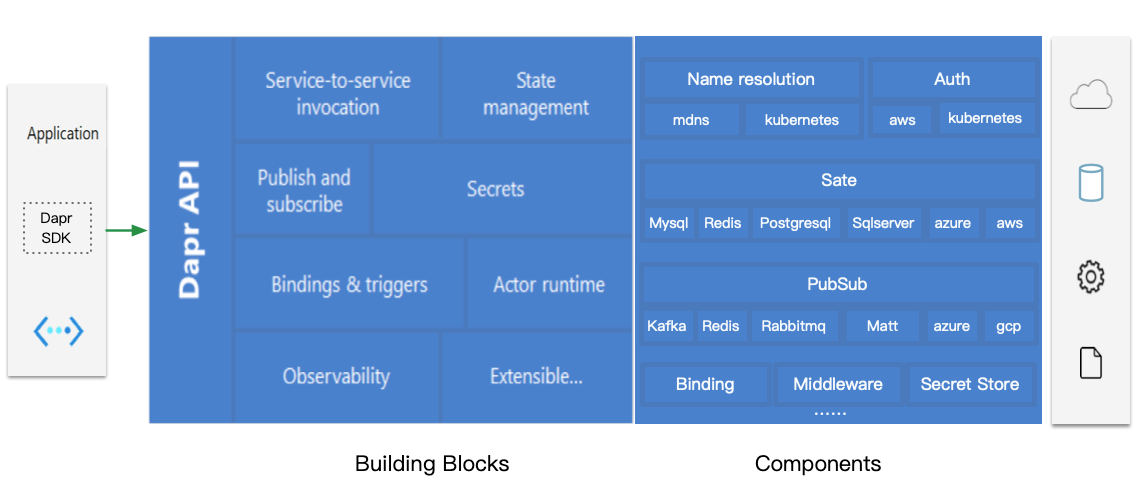
Together, these four layers form Dapr's core abstraction:
- Applications do not directly face concrete middleware. They face standard APIs.
- Standard APIs sit on top of distributed capability abstractions.
- Capability abstractions are backed by replaceable Components.
- These capabilities run outside the application, in a sidecar.
So Dapr is not an SDK. An SDK is a library embedded into the application, while Dapr moves many capabilities out of process. Dapr is not Service Mesh either. Service Mesh tries to be transparent to applications, while Dapr requires applications to call its APIs explicitly.
Dapr's Runtime Form: Sidecar and Control Plane
Dapr most commonly runs as a sidecar. This sidecar can be a standalone process during local development, or a sidecar container in Kubernetes.
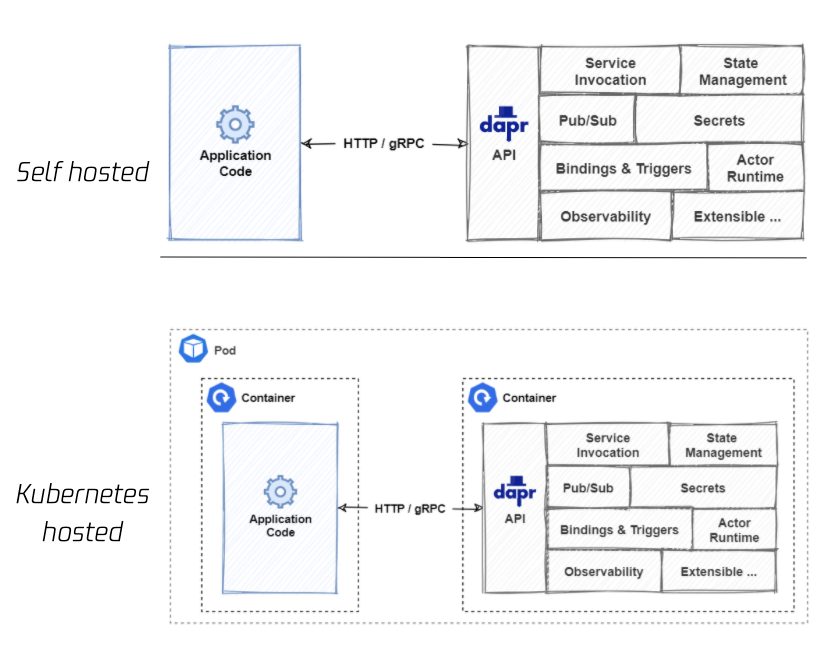
In Kubernetes, a workload enables Dapr through annotations. The Dapr Sidecar Injector injects a daprd container into the workload Pod. After the application starts, it accesses the Dapr sidecar through local ports. The sidecar loads Components based on configuration and exposes Building Block APIs, the metadata API, and the health API.
The Dapr control plane supports the operation of these sidecars:
- Sidecar Injector: injects the
daprdcontainer into Pods that enable Dapr. - Operator: watches resources such as Component, Configuration, and Resiliency, then provides configuration to the runtime.
- Sentry: handles certificate issuance and mTLS, enabling secure communication between sidecars and between sidecars and the control plane.
- Placement: manages Actor placement and synchronizes partition information.
- Scheduler: handles scheduling for Jobs, Actor reminders, and Workflow-related scenarios.
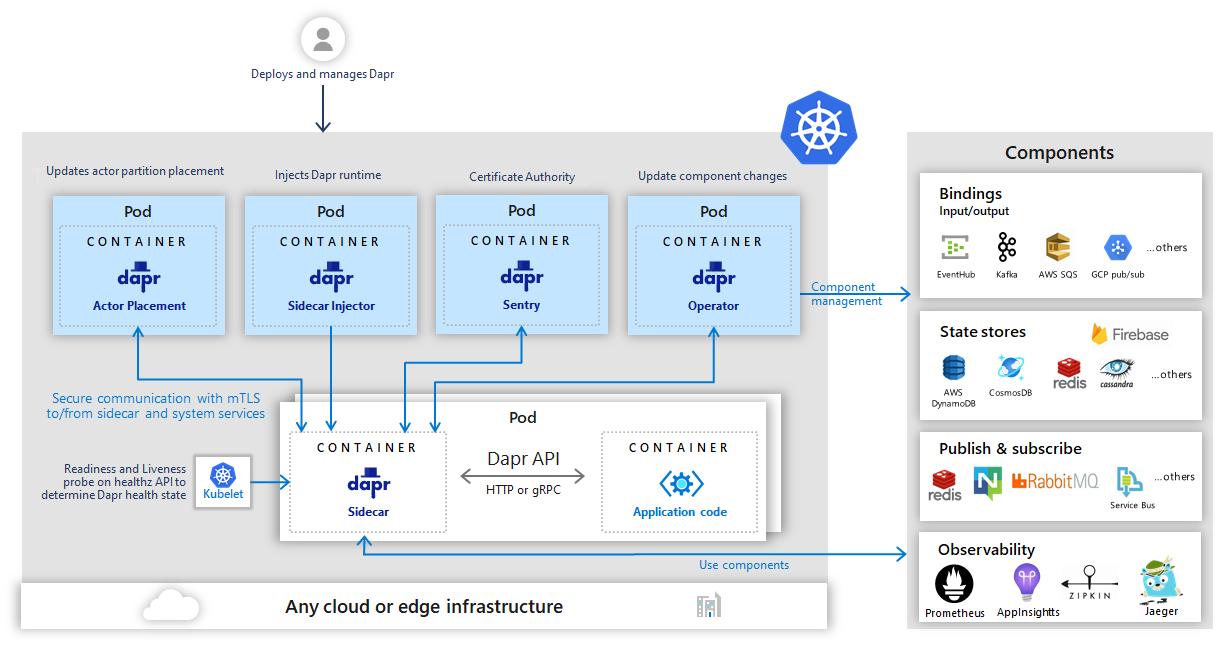
The benefit of this form is language neutrality. As long as an application can send HTTP or gRPC requests, it can call Dapr without being tied to a particular language framework. But it also means Dapr becomes part of the application's runtime path: each call gains an extra hop, troubleshooting gains another layer, and the platform gains another control plane and runtime component set.
The Three Categories of Distributed Problems Dapr Addresses
Dapr has many capabilities, but architecturally they can first be grouped into three categories: service communication, state consistency, and events plus orchestration.
The first category is service communication.
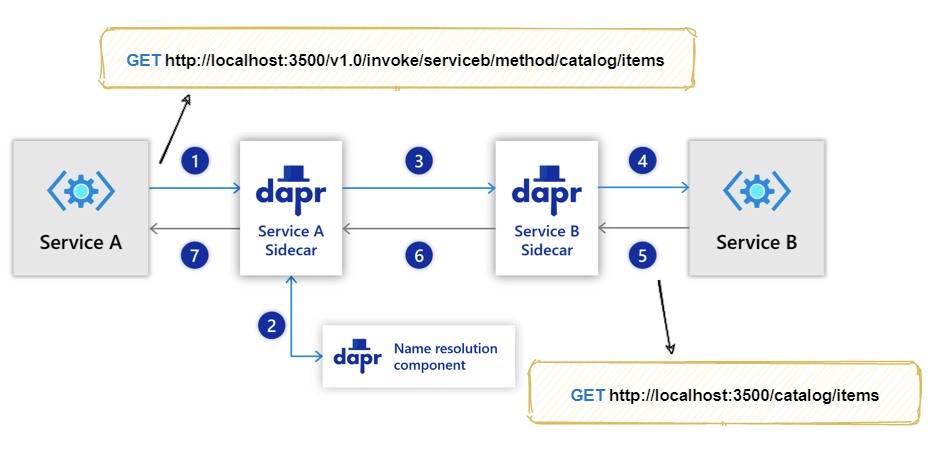
Dapr Service Invocation provides capabilities such as service discovery, service-to-service calls, mTLS, retries, timeouts, and observability. Applications identify target services by app-id and invoke them through Dapr APIs. The biggest difference from Service Mesh is that Dapr invocation is not transparent interception. The application must explicitly call the Dapr API.
This is one of Dapr's design trade-offs. Transparent interception is migration-friendly, but it is hard to express application-level semantics. Explicit APIs are intrusive to code, but they can express "which application and which method I want to call" more clearly. Dapr leans toward the latter.
The second category is state and consistency.
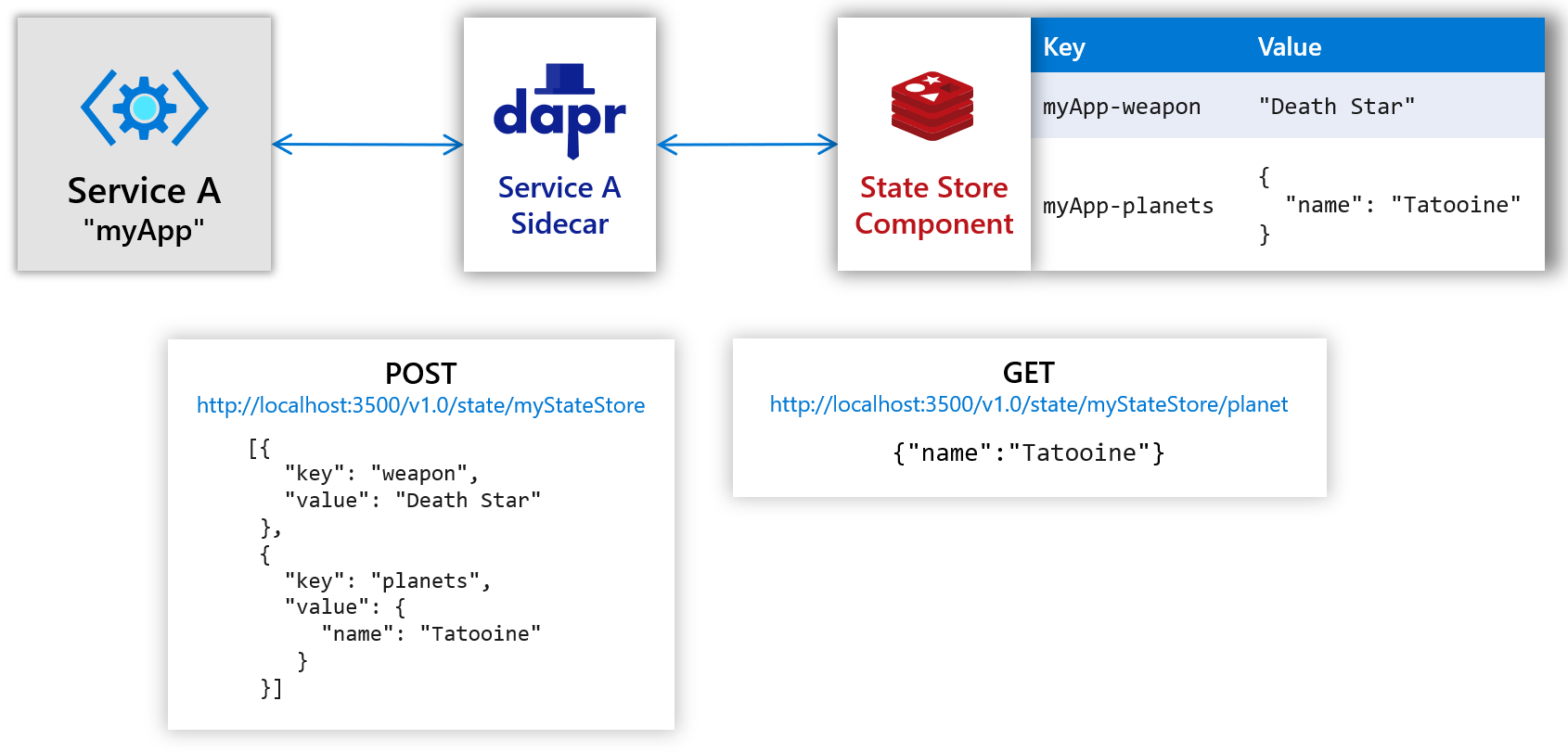
State Management gives applications a unified key-value state API. Applications can save, read, bulk read, and query state, and they can use state transactions on state stores that support transactions. Dapr also supports optimistic concurrency control through ETags: reads return an ETag, updates send the ETag back, and the update fails if the version does not match.
There is an important boundary here: Dapr unifies the access method, but it does not turn every storage system into an equivalent database. Different state stores do not support transactions, queries, consistency, ETags, TTL, and other capabilities in exactly the same way. Replaceable Components do not mean zero-cost migration for business logic. Abstraction can reduce coupling, but it cannot erase differences in the underlying systems.
The third category is events, external systems, and orchestration.
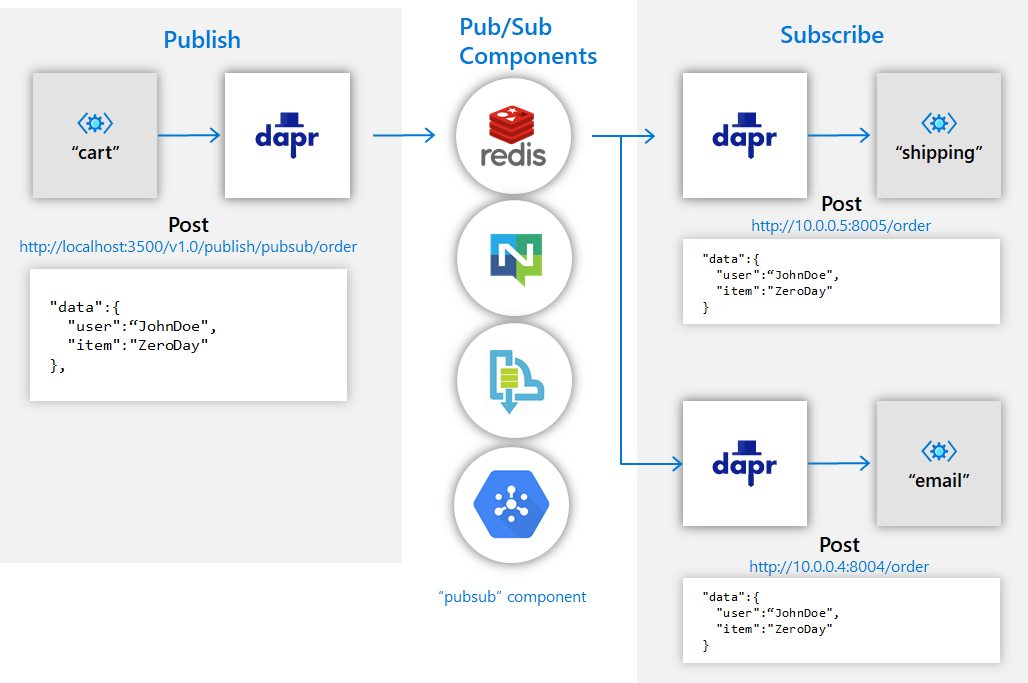
Pub/Sub decouples services through messaging. Dapr uses CloudEvents as the event format and provides at-least-once delivery semantics. Bindings are more about input and output between applications and external systems, such as reacting to external events, triggering external systems, integrating with cloud services, or connecting to third-party platforms.
Actors and Workflow are more focused on state and process orchestration. Actors encapsulate state and behavior into identity-bearing objects, which is suitable for modeling objects with independent state that need serial processing. Workflow provides higher-level long-running process orchestration, suitable for orders, approvals, account opening, deployment rollouts, and other business processes that span multiple steps, may last a long time, and require failure recovery.
Taken together, Dapr's core is not "I can also call Redis, Kafka, and HTTP services." It is about distilling the distributed patterns behind these calls into unified application primitives.
Complex Transactions: Dapr's Answer Is Not Distributed Transactions
When people see Dapr State, Pub/Sub, Workflow, Actors, and Distributed Lock, they naturally ask: can Dapr solve complex transactions?
The answer needs to be careful: Dapr can help with complex transactional business flows, but it does not turn cross-service transactions into a simple ACID transaction.
In microservice systems, a complex transaction is usually not a database transaction. It is a long-running business process. For example, after an order is created, the system may need to deduct inventory, create a payment order, send notifications, update membership points, and trigger fulfillment. If one step fails, the system must know which previous steps have completed, which steps should be retried, which actions need compensation, and which messages must not be processed twice.
Dapr takes a more realistic approach: it breaks this kind of problem into a combination of patterns.
Workflow handles long-running process orchestration. It expresses a cross-service business process as a recoverable workflow, suitable for flows that run for a long time, wait for external events, need retries, or require compensation. Workflow can be combined with Service Invocation, Pub/Sub, State, Bindings, and other capabilities.
Saga handles step-by-step execution and compensation. Each step should still be a local transaction. When a step fails, compensation actions restore the business semantics. For example, if inventory deduction fails, payment creation should not continue. If payment creation succeeds but later fulfillment fails, the system needs to cancel the payment or trigger a refund flow.
Outbox handles consistency between state changes and event publishing. In many systems, the problem is not "can the database run a transaction?" but "the state was written, but the message was not published" or "the message was published, but the state did not commit." Dapr's Outbox support can bind transactional updates in a state store with pub/sub message publishing, reducing the risk of inconsistency between state and events.
State Transaction handles transactions inside a single state store. Dapr state transactions depend on the underlying state store supporting transactions. They are not a global transaction coordinator across multiple databases and services.
ETags and idempotency handle concurrency and duplicate requests. Dapr can use ETags for optimistic concurrency control, but the business still needs to design idempotency keys, request deduplication, duplicate message handling, and compensation logic. Especially under Pub/Sub's at-least-once delivery semantics, consumers must assume that messages may be delivered more than once.
Distributed Lock is only a mutual-exclusion tool for limited scenarios. It can protect a shared resource so that only one instance operates on it at a time, but it should not be abused as a global transaction mechanism. Locks can reduce concurrency conflicts, but they cannot replace transaction boundaries, idempotency, compensation, or resource-side correctness checks.
So Dapr's answer to complex transactions is not "I provide a distributed transaction button." Instead, it provides a set of tools that better match microservice reality: Workflow orchestrates the process, Saga expresses compensation, Outbox connects state and events, State Transaction handles local transactions, and ETags plus idempotency handle concurrency and duplication.
This is also why Dapr is more valuable than an ordinary SDK. It does not only make a component easier to call; it places common distributed patterns in complex business flows into a unified runtime abstraction.
The Boundary Between Dapr and Service Mesh
Dapr is often compared with Service Mesh because both may use sidecars and both involve service invocation, secure communication, retries, and observability. But their goals are different.
Service Mesh sits at the network infrastructure layer. It tries to be as transparent as possible to applications, intercepting service-to-service traffic through proxies and providing capabilities such as mTLS, traffic governance, canary rollout, load balancing, fault injection, and observability. Ideally, application developers do not need to understand that the mesh exists.
Dapr sits at the application capability runtime layer. It does not aim for transparency. Instead, it requires applications to explicitly call Dapr APIs. It cares not only about how service A accesses service B, but also about how applications read and write state, publish events, receive external input, organize long-running processes, and read configuration and secrets.
The boundaries between several technologies can be roughly understood as follows:
| Layer | Main Problem It Solves | Typical Capabilities |
|---|---|---|
| Kubernetes | Application lifecycle and resource scheduling | Deployment, scheduling, scaling, health checks |
| Service Mesh | Service-to-service communication infrastructure | mTLS, routing, traffic governance, call observability |
| Microservice framework | In-application development model | Routing, RPC, dependency injection, framework conventions |
| Dapr | How applications consume distributed capabilities | State, events, invocation, Workflow, configuration, secrets |
Therefore, Dapr should not be understood as a replacement for Service Mesh. The two can coexist, but introducing both also increases complexity. If a system has both mesh sidecars and Dapr sidecars, the request path, resource overhead, troubleshooting, certificate system, and observability model all become more complicated.
A more reasonable way to judge is this: if your main pain point is service-to-service traffic governance, Service Mesh is closer to the problem. If your main pain point is how multilingual applications can uniformly consume state, events, external systems, and business orchestration, Dapr is closer to the problem.
Dapr's Boundary: Abstraction Is Not Free
Dapr's vision is attractive, but it is not a silver bullet. The benefits and costs of abstraction need to be considered together.
First, replaceable Components do not mean fully equivalent capabilities. Redis, PostgreSQL, MongoDB, Kafka, RabbitMQ, and cloud-provider services all have their own semantic differences. Dapr can unify the API, but it cannot make all underlying systems completely identical in transactions, consistency, queries, performance, and limits.
Second, the sidecar enters the critical path. When applications access state, publish messages, or invoke services, traffic goes through the Dapr sidecar. This brings language neutrality and moves capabilities downward, but it also brings extra hops, resource consumption, version management, and troubleshooting cost.
Third, explicit calls to Dapr APIs are themselves a form of coupling. Dapr reduces application dependency on specific middleware SDKs, but applications become dependent on Dapr's abstractions. This coupling is not necessarily bad, but it needs to be acknowledged architecturally.
Fourth, Dapr does not eliminate the complexity of distributed systems. Retries can still amplify traffic. Messages can still be duplicated. Workflow still needs version compatibility. Locks still need resource-side validation after lease expiration. State transactions are still limited by the capabilities of the underlying state store.
Fifth, not every system needs Dapr. If the system is small, the language stack is unified, and the state and messaging model is simple, using a framework and a few SDKs directly may be more straightforward. Dapr is better suited for systems that are multilingual, multi-team, multi-component, multi-environment, and genuinely need a unified abstraction for distributed capabilities.
Dapr's Value Is Not the Number of Features, but the Position of the Abstraction
The easiest misunderstanding of Dapr is to see it as "another microservice framework" or "a set of middleware SDKs." If you only look at the feature list, it does seem to package service invocation, state, messaging, bindings, Actors, Workflow, configuration, secrets, and other capabilities together.
But from the perspective of architectural evolution, Dapr's real value is not the number of features. It is the position of the abstraction.
Dapr consolidates part of the distributed capabilities that used to be scattered across business code, frameworks, SDKs, and infrastructure into an application runtime. Applications express intent through standard APIs, and Dapr maps that intent to concrete Components and runtime environments.
This makes Dapr especially suitable for several kinds of problems: multilingual applications want to share the same distributed capabilities; business systems need a degree of portability across infrastructure; teams want to reduce the intrusion of middleware SDK differences into business code; and systems involve complex event flows, state management, and long-running process orchestration.
But Dapr also has clear boundaries. It cannot replace database transactions. It cannot replace the full traffic-governance capabilities of Service Mesh. It cannot make complex systems automatically simple. What it provides is a better place to put things: distributed capabilities that are "not the business, but the business cannot live without them" can live outside the application, above the platform, and outside the framework.
This is probably what makes Dapr worth paying attention to: it is not inventing new distributed problems. It is answering an old question again: who should carry the complexity of distributed systems?
References
- Dapr Overview
- Dapr Building Blocks
- Dapr Sidecar Overview
- Dapr Services
- Dapr Workflow Overview
- Dapr Resiliency Overview
- Dapr State API
- Dapr Outbox
- Dapr Conversation Overview
- Multi-runtime Microservices Architecture